Олег Бартунов: Про «Postgres Pro»

Завтра рано утром я улетаю в Луклу навстречу треку, который я ждал целый год. Мы планируем пройти 5 высокогорных перевалов и 4 долины, увидеть еще раз высочайшие горы мира, ну и померзнуть в палатках, куда уж без этого. Моя голова уже почти отключилась от забот «того мира», но я попытаюсь объяснить зачем мы начали свои форки постгреса. Я уже наталкивался в сети на мифы вокруг наших сборок, что с одной стороны хорошо, ибо это означает, что дистрибутивами стали интересоваться и пользоваться, но это также означает, что мы недостаточно ясно пояснили наши мотивы. Поэтому я попробую это сделать сейчас, перед тем, как сдам ноутбук в камеру хранения.

Мне понравился этот монах, который стоически несколько часов стоял неподвижно, чем-то он был похож на отважного Щелкунчика. Я пожертвовал один раз, а потом не выдержал и положил денег еше раз.
Postgres Pro (он же Postgres Pro Standard), доступен с исходными текстами, включает некоторые наши патчи, которые уже попали в девелоперскую версию ванильного Постгреса, обычно отслеживает версии ванильного Постгреса, с которым сохраняет совместимость. Этим мы даем возможность пользователям быстрее попробовать новые фичи ванильного Постгреса.
Этот форк включает патчи для очистки памяти, проверки контрольных сумм бинарников и другие. Очевидно, что такие патчи сообществу совсем не нужны. Отмечу, что ванильный Постгрес недавно прошел сертификацию на Common Criteria, но на самый низший уровень, для которого не требовались дополнительные работы. Я надеюсь, что со временем ванильный Постгрес будет сертифицироваться на более высокие уровни и тогда мы сможем пропихнуть (отдадим) наши патчи безопасности и поддержка нашего форка станет легче.
(Примечание: это внутренняя условная нумерация, эти версии будут доступны пользователям под номерами, соответствующими актуальным релизам Postgres Pro)
История этого форка началась с совещания разработчиков Постгреса весной этого года (2016), на котором Саша Коротков представил план разработок Postgres Professional, который мы подготовили перед конференцией исходя из запросов наших клиентов. Наши планы вызвали большой интерес, другие компании тоже откликнулись своими планами, но мы не увидели желания сообщества что-то коренным образом менять. Много шумихи было вокруг версии 10.0, но ничего кардинального в ней не предполагается.
Где-то в июле 2016 года мы окончательно поняли (есть точная дата), что у сообщества другие интересы, а наши клиенты хотят новых фич уже сейчас, и нам надо самим начинать продвигать наши разработки в нашем собственном форке без оглядки на совместимость.
На этом разработки Postgres Pro Enterprise не заканчиваются, и мы обязательно напишем о них подробно. Мы также рассматриваем возможность включения поддержки 1С в энтерпрайз версию. Я надеюсь, что теперь понятна необходимость Postgres Pro Enterprise, которая в первую очередь предназначена для крупных клиентов.
На все эти продукты, а также на ванильный Постгрес, мы предоставляем техническую поддержку.
Мне кажется, что сейчас все должно быть кристально чистым.
Теперь про мифы. Чтобы написать про них, у меня не осталось времени и сил, так что просто дам ссылку на короткую презентацию «Russians in PostgreSQL» (видео), где я очень кратко показал 20-лет развития Постгреса и отметил российский вклад (красненьким цветом).
Пора мне паковаться, сдавать ноутбук в storage room, и немного поспать перед полетом в Луклу на маленьком самолетике, чтобы начать свой трек и окончательно раствориться в Гималаях. А вам всем желаю не ссориться, а просто принять тот факт, что мы создали нашу компанию Postgres Professional во благо всех, в том числе и ванильного Постгреса. Почитайте внимательно, если что-то непонятно, то проще прийти к нам в компанию и поговорить с нами, мы очень открыты, у нас проходят семинары, можно выступить, высказаться. На крайний случай, я доступен в ЖЖ, ФБ, ко мне обращаются сотни(!) людей, и я стараюсь со всеми быть откровенен и оказываю помощь. Этот месяц меня почти не будет в сети, я буду изредка что-то постить, чтобы показать прогресс нашего похода, но у меня не будет возможности оказывать профессиональную помощь, для этого вы можете воспользоваться контактами на нашем сайте.
Олег Бартунов, Postgres Professional — о независимости от импортного ПО и российском вкладе в самую популярную СУБД в мире
Созданные человеком программы берут данные и манипулируют ими, чтобы создавать новые, более ценные данные. Именно базы данных (СУБД) являются ядром любой информационной системы, хранящим как данные, которыми нужно манипулировать, так и полученную новую информацию. Из-за теоремы CAP не существует однозначного выбора между базой данных NoSQL или SQL. А растущая популярность БД NoSQL приводит к новым проблемам и моделям данных, которые традиционные реляционные базы не могут должным образом обработать. Основатель компании Postgres Professional Олег Бартунов рассказал «Хайтеку» об истории и перспективах одной из самых популярных СУБД в мире — PostgreSQL.
Читайте «Хайтек» в
Postgres как исконно российская СУБД
— Вы отстаиваете идею использования PostgreSQL в качестве национальной СУБД по программе импортозамещения. Это как многочисленные «национальные операционные системы» на базе Linux? Насколько вообще корректно называть продукт, созданный мировым сообществом, национальным?
— Да, действительно, в реестр отечественного ПО входят более 40 ОС на базе Linux различных российских производителей. Все эти операционные системы неравнозначны. К сожалению, в некоторых случаях мы имеем дело с простым переклеиванием ярлыков, порой даже грубым и неаккуратным. Но многие российские производители по-настоящему работают и делают патчи для ядра Linux, развивают и создают свои пакетные репозитории, участвуют в жизни международного сообщества и занимаются просветительской деятельностью.
СУБД — система управления базами данных.
PostgreSQL — свободная объектно-реляционная система управления базами данных. Существует в реализациях для множества UNIX-подобных платформ, включая AIX, различные BSD-системы, HP-UX, IRIX, Linux, macOS, Solaris/OpenSolaris, Tru64, QNX, а также для Microsoft Windows.
В случае с Postgres ситуация обстоит несколько иначе. С самого начала существования данной системы в ней было заметное российское участие. Когда Postgres стал open-source-проектом, в нем сразу принял участие программист из Красноярска Вадим Михеев, который написал несколько весьма значимых составляющих Postgres, актуальных и по сей день. Вскоре к проекту присоединился и я. Первым моим вкладом стала функциональность интернационализации, в том числе поддержка русского языка, которая позволила работать с алфавитами, отличными от латинского. И Postgres стал по-настоящему международным.

C годами отечественный вклад в Postgres только увеличивался. Появились Федор Сигаев и Александр Коротков, ставшие ведущими разработчиками. Вместе мы улучшили расширяемость Postgres: создали возможность эффективной и быстрой работы со слабоструктурированными данными (JSONB), разработали специализированные индексы для поиска по ним и по пространственным данным, создали полнотекстовый поиск. Этот вклад признан во всем мире.
JSONB — оптимизированный способ хранения данных в формате JSON, позволяющий извлекать данные без полного синтаксического разбора.
JSON (JavaScript Object Notation) — простой формат обмена данными, удобный для чтения и написания как человеком, так и компьютером. Он основан на подмножестве языка программирования JavaScript, определенного в стандарте ECMA-262 3rd Edition — December 1999. JSON — текстовый формат, полностью независимый от языка реализации, но он использует соглашения, знакомые программистам C-подобных языков, таких как C, C++, C#, Java, JavaScript, Perl, Python и многих других.
Есть и другой показатель вклада в СУБД — по количеству патчей, которые ежегодно поступают от участников из разных стран. Например, в release notes (замечания к версии программного продукта — «Хайтек») к 11-й версии упоминается около 25 человек с русскими фамилиями, из них 15 — сотрудники Postgres Professional. Это говорит о том, что российский вклад в Postgres больше, чем, например, вклад в население Земли или в мировой ВВП.
В условиях усиливающейся экономической глобализации единственный способ сделать свой национальный продукт (если не изобретать что-то кардинально новое) — это присоединиться к хорошему международному проекту с открытым кодом, внести в него свой вклад и достичь мирового признания.
Хочу обратить внимание, что в реестр отечественного ПО включен не open-source-продукт, а Postgres Pro — российская СУБД, права на которую принадлежат нашей компании. Она создана на базе Postgres с открытым кодом, но содержит существенные доработки, сделанные Postgres Professional по запросам наших клиентов — российских предприятий и организаций.
— Крупнейшие мировые производители СУБД предупредили российские компании, попавшие в санкционный список, о прекращении сотрудничества по всем проектам, начавшимся после 29 января 2018 года. К вам уже стоит очередь из сбербанков, газпромов и лукойлов?
— Для многих российских организаций остро встала проблема санкционной устойчивости. Поэтому они, даже не находясь под санкциями, задумываются о возможных последствиях в случае, если все-таки попадут под них. Вполне логично подстраховаться, поскольку впадать в полную зависимость от зарубежного ПО — неприемлемый риск для многих организаций. В связи с этим мы активно работаем со многими, хотя и не всеми, крупными российскими компаниями и государственными структурами, в том числе с Минфином России и Сбербанком.

— Чем принципиально отличаются свободно распространяемые и коммерческие версии PostgreSQL? Какой рост продаж у коммерческих версий?
В настоящее время мы наблюдаем усиление интереса к реальному импортозамещению в сфере ПО, которое в самые первые годы несколько буксовало. В связи с этим ожидается рост продаж Postgres Pro и положительная динамика.
— Есть ли «обратная связь» между ними, когда решения из коммерческого продукта переходят в свободно-распространяемый?
— В мире есть множество компаний, которые создают решения на базе открытого Postgres. Если говорить о крупных компаниях, то это американская EnterpriseDB, английская 2ndQuadrant, японская Fujitsu и российская Postgres Professional. Под разными названиями эти компании выпускают на базе Postgres свои продукты, рассчитанные на энтерпрайзный рынок. При этом все компании активно участвуют в разработке открытой СУБД и существенную часть своих разработок отдают мировому сообществу. Так устроена экосистема Postgres. Коммерческие разработки ориентированы на рынок, и потому ведутся более интенсивно, чем open-source-проект. В результате чего «ванильный» Postgres в условиях свободной лицензии получает от коммерческих продуктов больше, чем если бы его лицензия накладывала ограничения и не позволяла создавать коммерческие продукты.
Целые продукты из коммерческой сферы перешли в open-source — CitusDB или Greenplum, например. Именно свободной лицензии Postgres обязан нынешним бурным ростом в мировом масштабе. В то же время есть компании, которые ведут разработки на его базе и не делятся ими с мировым сообществом. Например, Amazon Web Services (AWS).
Развитие Postgres
— PostgreSQL уже можно смело называть PostgreNoSQL?
— При желании можно, но и это будет не совсем точно. Есть другой термин — Not Only SQL (с англ. «не только SQL» — «Хайтек»), который означает, что современные реляционные СУБД приняли вызов со стороны NoSQL и сейчас прекрасно работают со слабоструктурированными данными. Движение Postgres в этом направлении началось в 2004 году: тогда мы разработали модуль Hstore, благодаря чему PostgreSQL стал первой реляционной системы с поддержкой слабоструктурированных данных.

Следующий скачок был сделан через 10 лет, в 2014 году, когда мы реализовали поддержку формата JSONB. Этот формат представления данных позволяет не просто работать со слабоструктурированными данными, а делать это эффективно и быстро. Так что за этим сразу последовал рост популярности PostgreSQL во всем мире. И я связываю это с приходом NoSQL-ных пользователей. Сейчас JSON есть даже в стандарте SQL, и другие системы управления вслед за Postgres начали его поддерживать, но не столь эффективно.
Кстати, мы предпочитаем говорить не PostgreSQL, а Postgres — такое название проще произносится по-русски и признается сообществом. Именно так СУБД называлась до получения приставки SQL: изначально Майкл Стоунбрейкер разработал Postgres, потом она стала называться Postgres95 и, наконец, PostgreSQL.
SQL — декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных.
NoSQL — термин, обозначающий ряд подходов, направленных на реализацию систем управления базами данных, имеющих существенные отличия от моделей, используемых в традиционных реляционных СУБД с доступом к данным средствами языка SQL.
Майкл Стоунбрейкер — американский ученый в области информатики, PhD, исследователь проблематики построения систем управления базами данных, профессор Калифорнийского университета в Беркли, с 2001 года — профессор Массачусетского технологического института. Разработчик СУБД, основатель Ingres и VoltDB.
— В 2016 году широко обсуждалась новость об отказе Uber от PostgreSQL в пользу другого продукта. В качестве причин назывались проблемы с репликацией, особенно при смене версии продукта, повреждения данных при невинных операциях и ряда других. Что изменилось с тех пор?
— Как и у любого продукта, у Postgres имеются свои недостатки, но есть и способы их обойти. В свое время Uber решил не заниматься недостатками, а перейти на другую СУБД, с которой, вероятно, компания умела лучше обращаться. В то же время есть ничуть не менее нагруженные проекты, которые прекрасно работают на Postgres. Кроме того, в системе появилась логическая репликация, которой еще не было в 2016 году. Она обеспечивает бесшовную смену версий продукта. Также логическая репликация полностью пригодна для нагрузки «только на чтение». Ведется работа над исправлением ряда других проблем. В частности, в 12-й версии уже появился механизм подключаемых хранилищ, который в 13-й версии позволит создать подключаемое колоночное хранилище ZedStore и хранилище с UNDO-логом (ZHeap) (методы хранения и обработки данных в Postgres — «Хайтек»). И это сократит объем записи на диск.

— Когда мы увидим PostgreSQL не как продукт, а как облачный сервис?
— Облачные сервисы на базе Postgres уже есть. За рубежом подобными сервисами занимается множество компаний, в том числе Amazon, Google, Alibaba и Microsoft. В России такой сервис предоставляют Яндекс и Mail.Ru. При этом количество облачных сервисов будет расти как в нашей стране, так и за рубежом.
Но чтобы Postgres полноценно использовал преимущества облачной среды, в него необходимо вносить ряд существенных изменений. Тогда производительность в облачной среде будет почти такой же высокой, как и в обычном режиме. Мы занимаемся такими разработками.
Postgres как наука
— Помимо прекрасного продукта, который вот уже более 20 лет использует весь интернет, вы развиваете и само СУБД-строение. Существуют ли какие-то русскоязычные курсы по технологиям построения, чтобы по ним можно было изучать предмет в вузах?
— Да, мы мечтаем о том, чтобы отрасль СУБД-строения динамично развивалась в нашей стране. Безусловно, для этого необходимо готовить специалистов, знающих архитектуру и внутреннее устройство. Для содействия развитию этого направления мы пригласили профессора из Санкт-Петербургского государственного университета — Бориса Асеновича Новикова. Это научный деятель мировой величины в сфере систем управления. При нашей поддержке он написал учебник «Технологии баз данных». Первый том уже вышел. Сейчас идет работа над вторым. Борис Асенович по нашему приглашению также прочитал свой курс в МГУ в качестве межфакультетского факультатива. Видеозаписи постепенно выкладываются на сайте Postgres Professional, и с тремя лекциями этого курса уже можно ознакомиться.
Также при нашей поддержке доцент СибГУ имени М. Ф. Решетнева Евгений Павлович Моргунов разработал спецкурс «Язык SQL», позволяющий обрести фундаментальные знания в области систем управления базами данных. Второй год подряд этот курс с успехом читается в стенах ВШЭ. В качестве дополнения при поддержке компании Postgres Professional выпущен учебник «PostgreSQL. Основы языка SQL».
Весной этого года впервые в России мы запустили программу сертификации специалистов по PostgreSQL. Поскольку специалисты по Postgres становятся все более востребованными на российском рынке, необходимы единые стандарты и критерии для оценки уровня знаний. Во многом наша программа сертификации стала ответом на запросы заказчиков и партнеров.
— Каким вы видите будущее СУБД через 10–20 лет? Объектно-реляционные системы еще будут находить применение?
— Да, они еще будут находить применение. Эти СУБД базируются на строгой математической теории, и она еще долго будет актуальной. Мы не видим никаких причин, чтобы те прикладные задачи, для решения которых нужна классическая система, куда-то исчезли.

Но вопрос не только в том, что данных становится очень много. Если раньше операционные и аналитические системы, то есть базы данных и вычисления были разнесены между собой, то сейчас вычисления приближаются к данным и в идеале должны совершаться одновременно с их поступлением. Так что уже недостаточно одной технологии OLTP — обработки транзакций в режиме реального времени. И недостаточно онлайн аналитики данных, то есть OLAP. На передний план выходит гибридная транзакционно-аналитическая обработка данных (HTAP), способная в режиме реального времени и стриминга совершать обработку данных и транзакций. При этом достигается высокое быстродействие, так как данные не нужно переносить из базы для вычислений, данные транзакций сразу доступны для аналитики с момента их создания. Так что технология HTAP наряду с облаками будет задавать тон в плане долгосрочного развития СУБД.
Тонкости эксплуатации, плюшки и особенности Postgres Pro Enterprise
7 лет пути
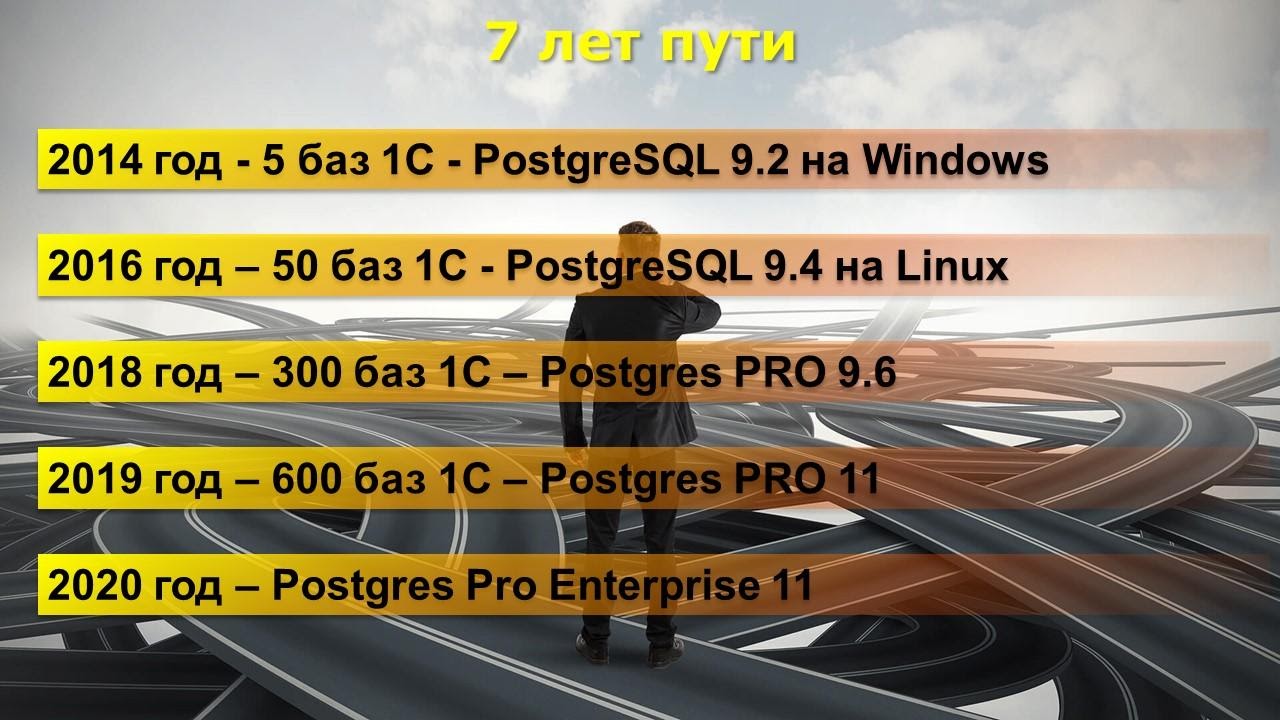
Расскажу для начала, какой путь мы прошли в 1С на PostgreSQL.

Версии Postgres для 1С
Но прежде чем окунуться в Enterprise, сначала напомню, какие версии PostgreSQL для 1С есть. В этом моменте у многих есть недопонимание.
PostgreSQL для 1С – самосборка

Версия №1 – это самосборка PostgreSQL для 1С на основе открытых исходников ванильной версии. Для тех, кто умеет собирать пакеты – это самая теплая ламповая сборка.
В чем ее особенности использования:
PostgreSQL для 1С – сборка фирмы «1С»

Есть сборка PostgreSQL от фирмы «1С». Она распространяется в двух видах – как дистрибутив и в качестве исходников набора патчей, которые нужно использовать для ванильного PostgreSQL.
В чем ее особенности:
PostgreSQL для 1С от Postgres PRO

Следующая сборка появилась недавно, в день проведения конференции Infostart Event 2019, от команды Postgres PRO. О ней объявил Олег Бартунов. Это сборка от команды Postgres PRO, скачать ее можно с сайта https://1c.postgres.ru. Это – ванильный Postgres, собранный с патчами для 1С и плюс некоторые улучшения, которые команда Postgres PRO считает важными для 1С и внедряет их.
Postgres PRO Standart

Еще одна такая же сборка с небольшой цензурой Postgres PRO Standart.
Получить ее можно, зарегистрировавшись на сайте Postgres PRO.
Postgres PRO Enterprise

Коммерческая сборка Postgres PRO Enterprise – чем она отличается от версии Postgres PRO Standart:
Фишки Enterprise, полезные для 1С

Теперь подробнее поговорим о фишках Enterprise, которые важны именно для 1С.
Все отличия Enterprise от не-Enterprise смотрите по ссылке https://postgrespro.ru/products/postgrespro/enterprise.
Теперь давайте подробнее рассмотрим, как это в жизни работает.
pg_hint_plan

pg_hint_plan – это не фишка Enterprise, это открытое расширение, которое вы можете спокойно внедрять в свои сборки, но в Enterprise оно уже внедрено.
Что оно делает? На просторах интернета можно встретить жалобы на то, что в 1С плохо работает отчет. Но если в настройках join_collapse_limit поставить 1 (вместо 8 или 20 – по умолчанию на разных сборках установлено по-разному), то отчет сразу начинает работать быстро, а вся остальная база «встает колом».
Для решения такого вида проблем есть pg_hint_plan. Вы можете влиять на план выполнения запроса, добавляя в комментариях нужные вам операторы, как показано на слайде.
Конкретно этот пример взят мной из документации. Здесь указано:
Ниже план выполнения, где видно, что Postgres выполняет команды так, как ему сказали.
Таким образом, независимо от того, как отработал планировщик – “Бог” СУБД, вы как программист можете выступить «помощником Бога» и исправить ошибки “Бога” так, как считаете нужным. Не факт, что это будет правильно или быстрее, но эксперты вполне могут себе позволить это делать.

Скорее всего, у вас не получится напрямую засунуть комментарий в код 1С так, чтобы платформа это правильно обработала и передала. Но в этом расширении есть крутая штука – таблица указаний, где вы можете шаблонно указать запрос и что с ним сделать.
Тут надо иметь в виду одну особенность – шаблон запроса это не маска, хоть и называется шаблоном. Чтобы эта настройка сработала, запрос должен прилетать всегда одинаковый.
А с помощью указания Set вы можете на время планирования запроса задать планировщику параметры GUC (например, указать join_collapse_limit=1 на ваш любимый отчет) – получается, что и запрос ускорится и база летать начнет.
Подробно запросы разбирать я не буду, но это незаслуженно забытое расширение, изучите его. Документации по нему много, очень крутая вещь, будущее у нее есть.
Поскольку не всегда мы можем дождаться исправления в платформе 1С, где, по нашему мнению, неправильная интерпретация запросов. А здесь вы можете сами взять и что-то подправить в планировщике.
Сжатие данных на уровне СУБД

Что дает сжатие данных на уровне СУБД:
Казалось бы, сжатие – крутая вещь, но когда мы ее начали использовать на 1С, нас начало не по-детски “штормить”.

На тот момент у нас были настройки сжатия, как на слайде. Не было только одной настройки – Compress first segment of relations.
Что это такое? По умолчанию сжатие происходит вообще всех элементов базы данных. Опять же напоминаю, что типовая Бухгалтерия содержит 5,5 тысяч таблиц и 27 тысяч индексов – итого 32 тысячи файлов.
Кроме того, Postgres каждый следующий гигабайт пишет в новый файл. Может быть, что одна наша база данных займет 300 тысяч файлов.
По умолчанию CFS попробует сжать все 300 тысяч файлов.
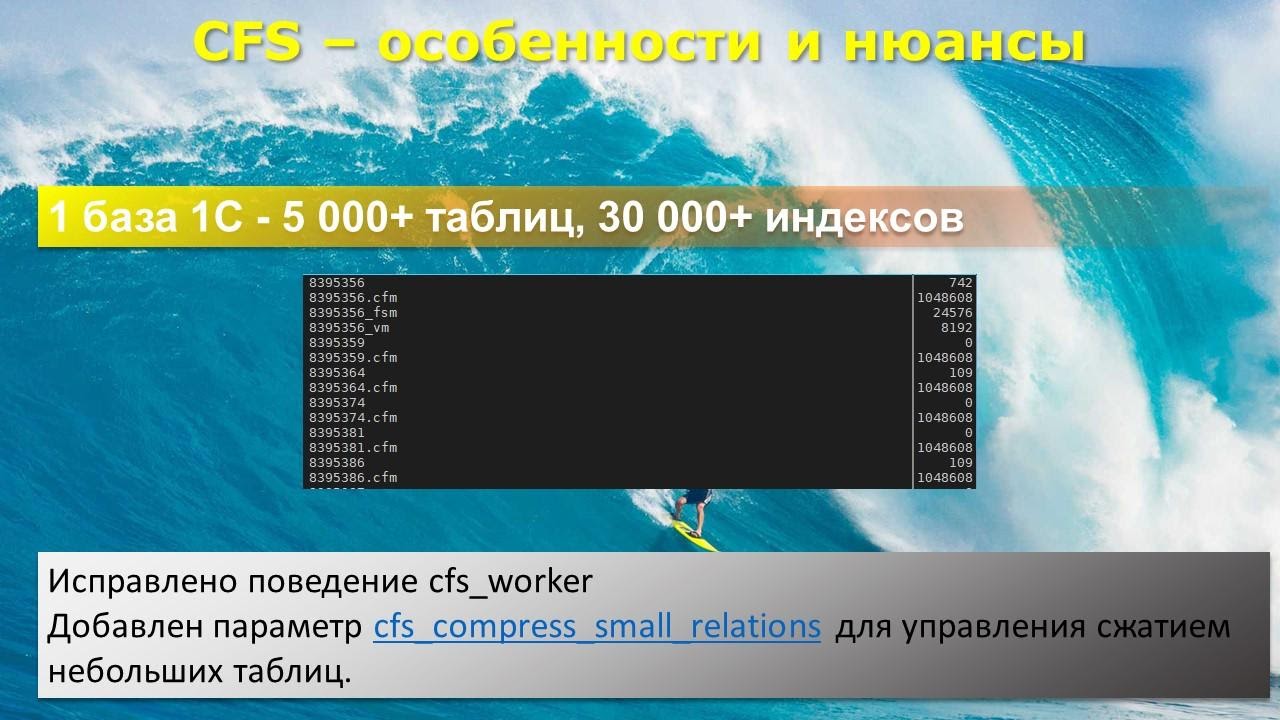
В результате мы получим у каждой базы вот такой файл-отражение со стандартным размером 1 мегабайт, поскольку именно в 1 мегабайте они могут удержать отражение 1 Гб данных.
Postgres не знает, что его сжали, он обращается к номеру страницы на диске, который у него в базе написан.
Система сжатия перехватывает этот запрос, и запрашивает в CFM-файле, где эти данные теперь в реальности находится – мы же сжали файлы, а оригиналы, грубо говоря, удалили, они находятся в другом месте. Это и называется файл-отражение, когда на каждый элемент создается файл размером 1 мегабайт.
В чем случилась беда? Наш первый тест на базе 1С показал следующее: CFS-worker бегает по всем файлам отражения и пытается их дефрагментировать – удалить оттуда то, что мы удалили из данных. Грубо говоря, еще один вакуум еще одного элемента. При таком количестве файлов, как в базе 1С, CFS-worker клали на лопатки любые дисковые системы. У нас система легла на 4 млн файлов – это 150 баз на сервере 1С.
После этих тестов разработчики PostgreSQL:

Дальнейшие исследования показали, что нельзя сжать табличное пространство по умолчанию. Изначально Postgres ставится и создает пространство-default. Но сжать уже созданное пространство нельзя, сжатие происходит путем создания пространства с сжатием.
Здесь можно пойти несколькими путями:

Как я уже сказал, каждый файл отражения весит 1 МБ, но это не реальное место, которое занимает файл на диске, а просто атрибут файла. В итоге можете получить интересный эффект. После сжатия 100-гиговой базы в свойствах Postgres вы обнаружите, что 100-гиговая фаза начала весить 250 гигов. Как же так, мы же сжали? Все просто: у вас образовалось 150 тысяч файлов отражений. Это пока не исправлено, нет отдельной процедуры, которая показывает правильный размер, либо я о ней не знаю.
Реальный размер в Linux проверяется через утилиту du (disk usage) – на слайде приведена командная строка, как проверять. Эта утилита покажет вам реальный размер, который данные занимают на диске, а не размеры, подсчитанные по атрибутам файлов. В pg_admin будет искаженная информация.

Еще одна особенность, обнаруженная случайно: оказывается, утилита pg_repak (по факту vacuum_full без блокировки данных), знает, но не учитывает tablespace у таблиц.
А поскольку при сжатии мы создаем отдельный tablespace, то pg_repack, когда вы натравите его на сжатую базу, перепакует таблицы в несжатое пространство, в default.
Что изменится в августе
Когда мы это все раскопали, нам показалось, что в целом можно запускаться. Но мы нарвались на две ошибки, которые нам обещают исправить в августе.

Я впервые встречаю вендора, с разработчиками которого можно общаться напрямую на русском языке, и они тебе отвечают в течение одной минуты, не ткнут носом в ошибку, пытаются разобраться и очень быстро и аккуратно исправляют баги.
Итак, когда мы подумали, что все окей, мы, как правильные эксплуататоры СУБД, решили настроить реплику и нарвались там на две ошибки. Эти ошибки нам обещают исправить в августе. Что это за ошибки?
С 1 сентября, когда с нас снимут все карантины, заодно мы получим полностью работающую Enterprise версию PostgreSQL со сжатием данных. Огромное спасибо разработчикам движка базы данных и моей команде 1С-ников, которые все это протестили.
P.S. Все исправления обнаруженных нами проблем со сжатием вошли в версию 12.5.1.
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Новосибирск. Больше статей можно прочитать здесь.
Приглашаем всех принять участие в INFOSTART EVENT 2021 (6-8 мая, СПб).



