Ceph в ProxMox на ZFS
В своей работе (системный администратор) приходится всегда искать вещи и знания, уникальные для своего региона. Одной из таких вещей в нашей конторе является ProxMox, поставленный на файловой системе ZFS, позволяющей использовать неплохой raid массив без использования железных контроллеров. Однажды, думая, чем можно еще удивить и порадовать клиентов, мы решили всё это водрузить на распределенную файловую систему Ceph. Не знаю уж, насколько было такое решение адекватным, но я решил воплотить желание в жизнь. И тут понеслась… Я перелопатил горы статей и форумов, но так и не нашел одного адекватного мануала, описывающего в подробностях что и как делать, поэтому, справившись со всем, родилась эта статья, кому интересно, добро пожаловать под кат.

Итак, в принципе, всё делается в консоли и веб-морда ProxMox нам особо не нужна. Делал я всё в тестовом режиме, поэтому было поднято две виртуалки с четырьмя дисками внутри не очень мощного по железу проксмокса (этакая матрёшка). Четыре диска изначально были обусловлены тем, что хотелось поднять, как и на будущем уже не тестовом железе, на ZFS10, но не вышла золотая рыбка по неведомым мне причинам (на самом деле, было лень разбираться). Вышло так, что ProxMox не смог разметить ZFS10 на виртуальных дисках, поэтому было решено использовать немного другую “географию”. На одном из дисков ставился собственно сам ProxMox, на двух других поднимался ZFS1, третий был якобы под журнал Ceph, но я в итоге про него забыл, поэтому пока оставим его в покое. Итак, приступим.
Тут будет небольшая вводная:
Проксмокс у нас свежеустановленный в двух местах. Ноды называются ceph1 и ceph2. Делаем на обеих нодах всё одинаково, кроме тех мест, что я обозначу. Сеть у нас 192.168.111.0/24. Первая нода (ceph1) имеет адрес 192.168.111.1, вторая (ceph2) — 192.168.111.2. Диски на обеих нодам имеют следующие значения: /dev/vda — диск, на котором стоит ProxMox, /dev/vdb и /dev/vdc — диски, предназначенные для ZFS, /dev/vdd — диск для журнала Ceph.
Первое, что нам нужно сделать, это поменять платный репозиторий ProxMox, требующий подписки, на бесплатный:
Там комментируем единственную строку и вписываем новую ниже:
Далее обновляем наш ProxMox:
Устанавливаем пакеты для работы с Ceph:
Следующим шагом нам нужно сделать кластер из проксмоксов.
На первой ноде выполняем последовательно:
где mycluster — это имя нашего кластера.
Соглашаемся с тем, что нужно принять ssh ключ и вводим пароль root от первой ноды.
Проверяем всё это дело командой pvecm status
Далее инициализуруем конфигурацию Ceph (делается только на первой ноде, которая будет “главной”):
это создаст нам симлинк на /etc/ceph/ceph.conf, от которого мы будем далее отталкиваться.
Сразу после этого нам надо добавить туда опцию в раздел [osd]:
Это связано с тем, что ZFS не умеет directIO.
Следующее, чем делаем, это готовим наш ZFS пул. Для этого диски нужно разметить в GPT:
Там последовательно нажимаем g и w (g для создания таблицы GPT и w для принятия изменений). То же самое повторяем на /dev/vdc.
Создаем зеркальный ZFS пул, называться он у нас будет как принято в ProxMox – rpool:
ZFS пул у нас создан, пришло самое время заняться самым главным — ceph.
Создадим файловую систему (странное название, но оно взято с доки по ZFS) для нашего монитора Ceph:
Создадим сам монитор (сначала на первой ноде, потом на второй):
Далее начинается то, с чем пришлось повозиться, а именно то, как сделать блочное устройство для Ceph OSD (а он именно с ними и работает) в ZFS и чтобы оно еще и работало.
А делается всё просто — через zvol:
90G — это то, сколько мы отдаем нашему Ceph на растерзание. Так мало потому, что сервер виртуальный и больше 100G я ему не давал.
Ну и сделаем сам Ceph OSD:
—fs-type у нас выбран XFS потому, что XFS — это дефолтная ФС у Ceph. FSID — это ID нашего Ceph, который можно подсмотреть в /etc/ceph/ceph.conf. Ну, и /dev/zd0 — это наш zvol.
значит что-то пошло не так и вам либо нужно перезагрузиться, либо ещё раз нужно выполнить создание ceph OSD.
В общем то, на этом мы уже сделали наш ceph и можно дальше им рулить уже в вебморде ProxMox и создать на нем нужное RDB хранилище, но вы не сможете его использовать (собственно, ради чего всё это затевалось). Лечится простым способом (для этого всё-таки хранилище надо создать) — нужно скопировать ключ ceph с первой ноды во вторую.
Открываем конфиг хранилищ ProxMox:
И вписываем туда нужный нам RBD:
Здесь test — это имя нашего хранилища, а IP адреса — это то, где находятся ceph мониторы, то есть наши проксмоксы. Остальные опции дефолтные.
Дальше создаем папочку для ключа на второй ноде:
И копируем ключ с первой:
Здесь ceph1 — наша первая нода, а test — имя хранилища.
На этом можно ставить точку — хранилище активно и работает, можем пользоваться всеми плюшками ceph.
Спасибо за внимание!
Для того, чтобы всё это поднять, пользовался данными ссылками:
Proxmox. Ceph
Продолжаем знакомство с Proxmox VE.
Ceph — это распределенное хранилище объектов и файловая система, предназначенная для обеспечения отличной производительности, надежности и масштабируемости.
Proxmox VE объединяет вычислительные системы и системы хранения. Это позволяет локальные хранилища (диски) объединять в одно гиперконвергентное устройство. Благодаря интеграции Ceph, Proxmox VE имеет возможность запускать и управлять хранилищем Ceph непосредственно на узлах гипервизора.
По сути получаем вместо SAN или NAS хранилищ объединенное распределенное отказоустойчивое гиперконвергентное устройство (хранилище).
Данная технология реализована у VMware (VMware Virtual SAN) и Microsoft (Storage Spaces Direct).
Познакомиться с Ceph можно в этой статье: Знакомство с хранилищем Ceph в картинках.
Установка Ceph
Установим на всех нодах кластера:
Определим сети и назначим ноду монитора:
Готово. Установим на остальных нодах. Поскольку конфигурация в кластере уже установлена вместе с первой нодой, на остальных нодах этого не потребуется.
Если необходимо можно создать дополнительные мониторы:
На всех нодах добавляем диски в OSD:
И создаем Metadata Server:
Создаем хранилище в кластере CephFS:
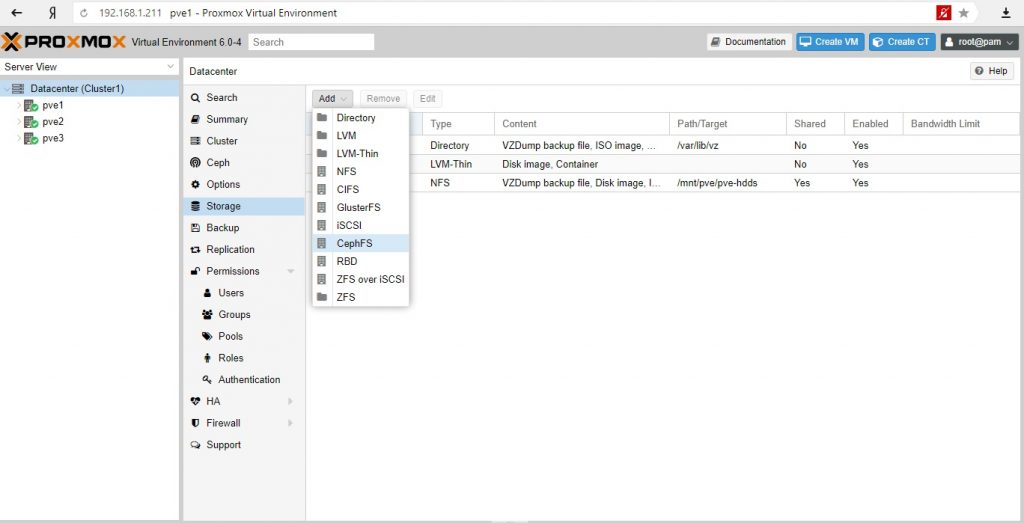
CephFS – поддерживает тип хранилищ ISO images, VZDump backup, Container template, Snippets.
Для размещения дисков виртуальных машин и контейнеров нужно создать RDB Storage.
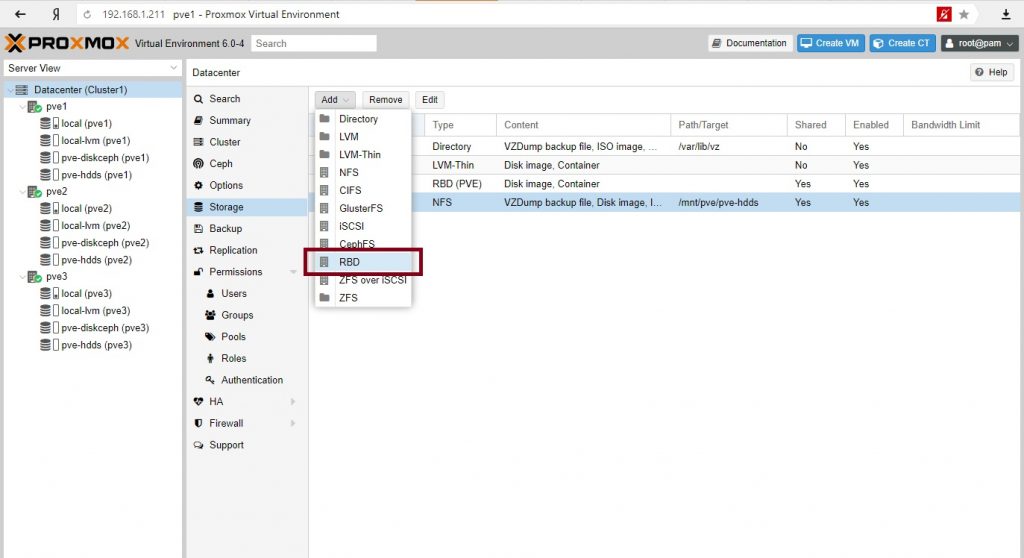
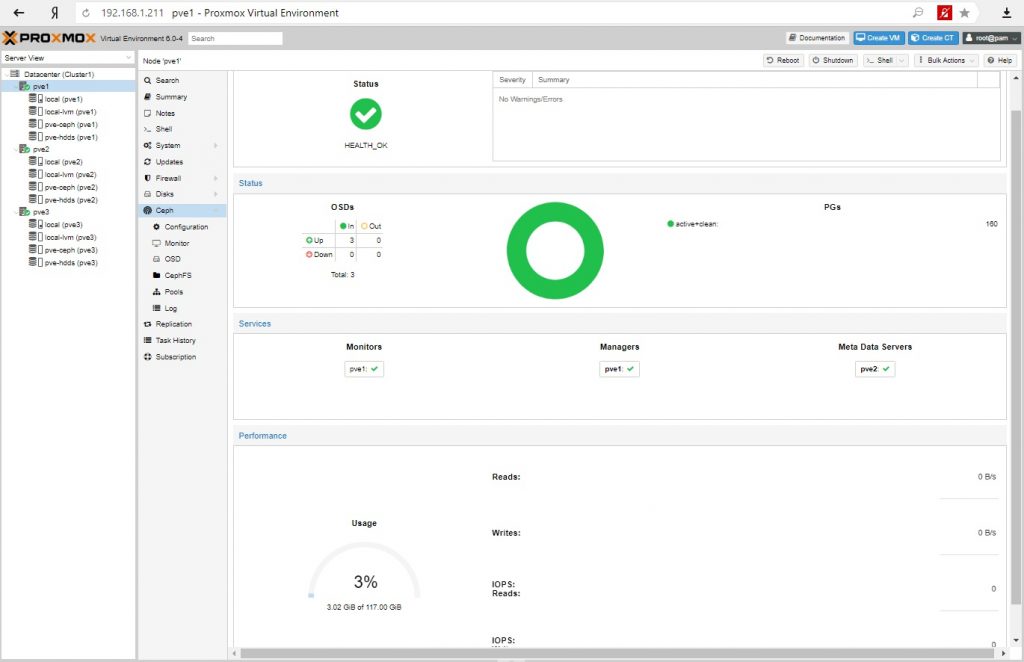
Далее добавим еще один сервер монитор и Metadata Server.
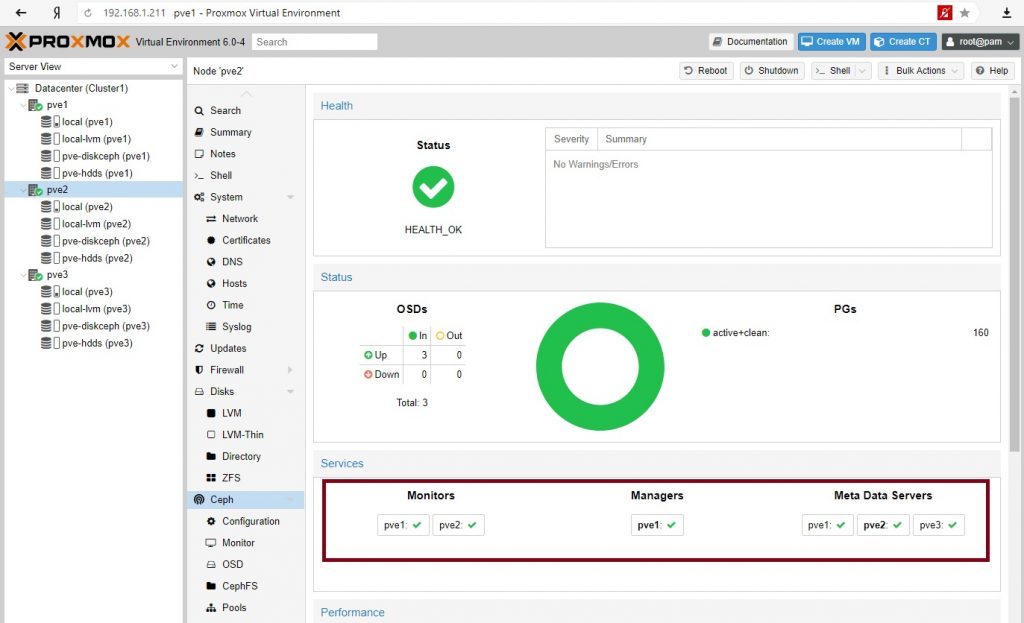
Создаем виртуальную машину или контейнер с размещением на Ceph (RDB) и тестируем работоспособность, возможность миграции между нодами.
Пример: Создан контейнер с веб сайтом (phpBB) на PVE3 с размещением на Ceph (RDB) диске. Создан ресурс высокой доступности (HA Resource) на контейнер. После выключаем ноду PVE3.
Результат. Контейнер мигрировал на рабочую ноду, сохранив работоспособность, Ceph деградировал, но сохранил работоспособность.
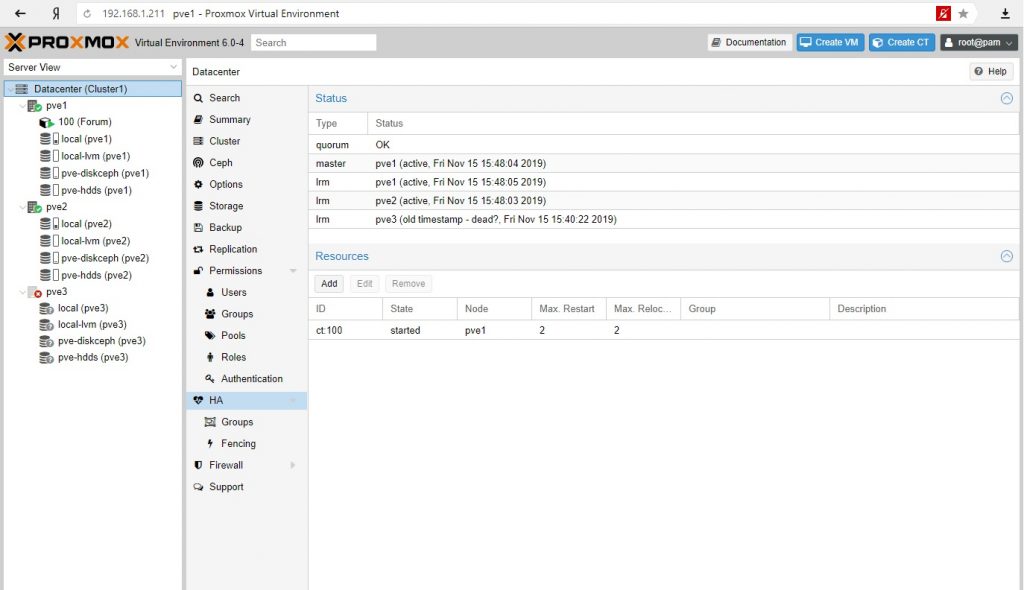
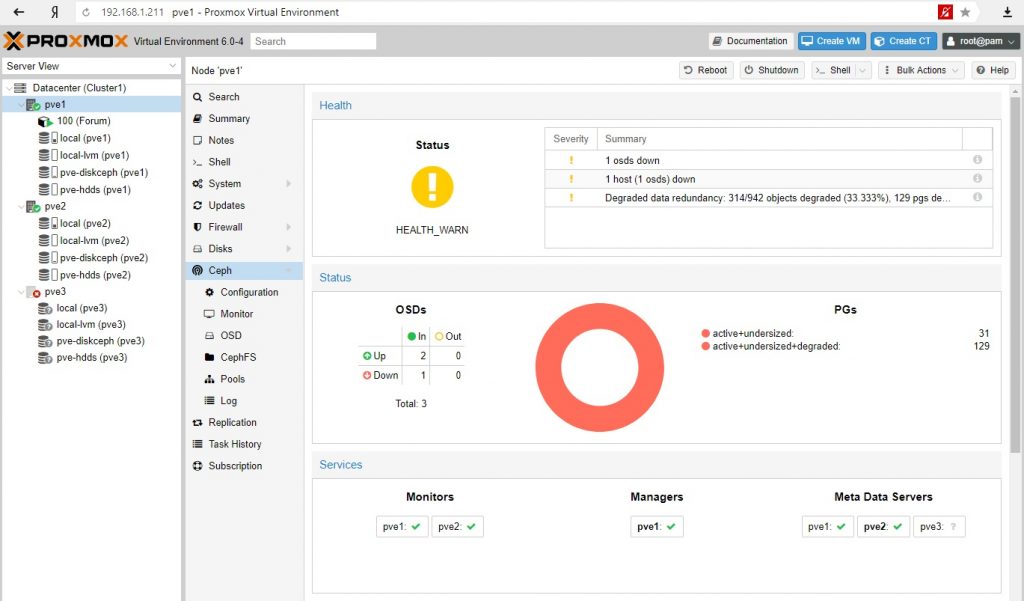
Восстановим работоспособность PVE3 и проверим данные.
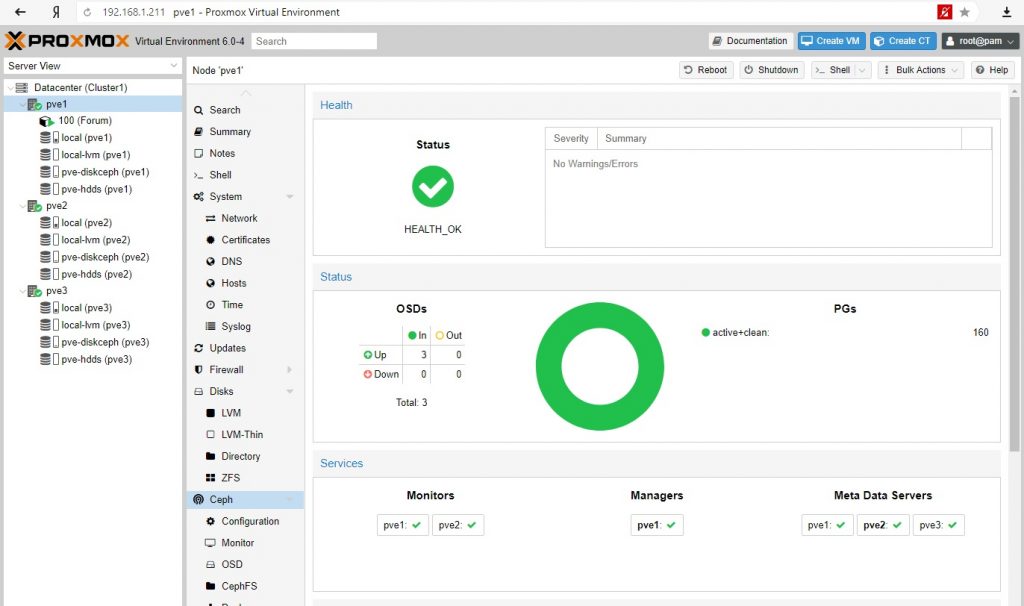
Тема с гиперковергентыми устройствами и средами достаточно масштабна и наряду с преимуществами имеет не меньше подводных камней, сложностей и проблем. В рамках одной статьи невозможно продемонстрировать все нюансы технологии. Однако можно сказать, что, чем больше объектов будет учувствовать в данной среде, тем больше устойчивость среды к отказам.
Администрирование и не только
Не вполне стандартные задачи, с которыми мне приходится сталкиваться по работе и способы их решения.
Страницы
вторник, 5 ноября 2019 г.
Руководство администратора Proxmox VE R 6.0 Глава 4.
Гиперконвергентная инфраструктура
Преимущества гиперконвергентной инфраструктуры (HCI) с Proxmox VE
Управление службами Ceph на узлах Proxmox VE

Предварительное условие
Для построения гиперконвергентного кластера Proxmox + Ceph должно быть как минимум три (желательно) одинаковых сервера для установки.
Проверьте также рекомендации с веб-сайта Ceph.
CPU
Более высокая частота ядра процессора уменьшает задержки и является предпочтительной. В качестве простого практического правила вы должны назначить ядро (или поток) процессора каждому сервису Ceph, чтобы обеспечить достаточно ресурсов для стабильной и надежной работы Ceph.
Память
Особенно в гиперконвергентной установке, потребление памяти необходимо тщательно контролировать. В дополнение к предполагаемой рабочей нагрузке от виртуальных машин и контейнера, Ceph требуется достаточно памяти, чтобы обеспечить хорошую и стабильную производительность. Как правило, для примерно 1 TiB данных, 1 GiB памяти будет использоваться OSD. Кэширование OSD будет использовать дополнительную память.
Сеть
Мы рекомендуем пропускную способность сети, которая используется исключительно для Ceph не менее 10 GbE или более. Ячеистая топология сети 2 также является выходом, если нет доступных коммутаторов 10 GbE. Объем трафика, особенно во время восстановления, будет мешать другим службам в той же сети и может даже разрушить стек кластера Proxmox VE. Кроме того, оцените свои потребности в пропускной способности. В то время как один жесткий диск может не насыщать канал 1 Гб, несколько жестких дисков на узле могут, а современные накопители SSD NVMe даже быстро насыщают пропускную способность 10 Gbps. Развертывание сети, способной к еще большей пропускной способности, гарантирует, что это не ваше узкое место и не будет в ближайшее время, возможно 25, 40 или даже 100 Gbps.
Внимание! Избегайте RAID-контроллера, используйте вместо него host bus adapter (HBA). Примечание Приведенные выше рекомендации следует рассматривать как примерное руководство по выбору аппаратного обеспечения. Поэтому по-прежнему важно адаптировать его к вашим конкретным потребностям, протестировать вашу установку и постоянно контролировать работоспособность и производительность. 2 Полная ячеистая сеть для Ceph https://pve.proxmox.com/wiki/Full_Mesh_Network_for_Ceph_Server
Начальная установка и настройка Ceph

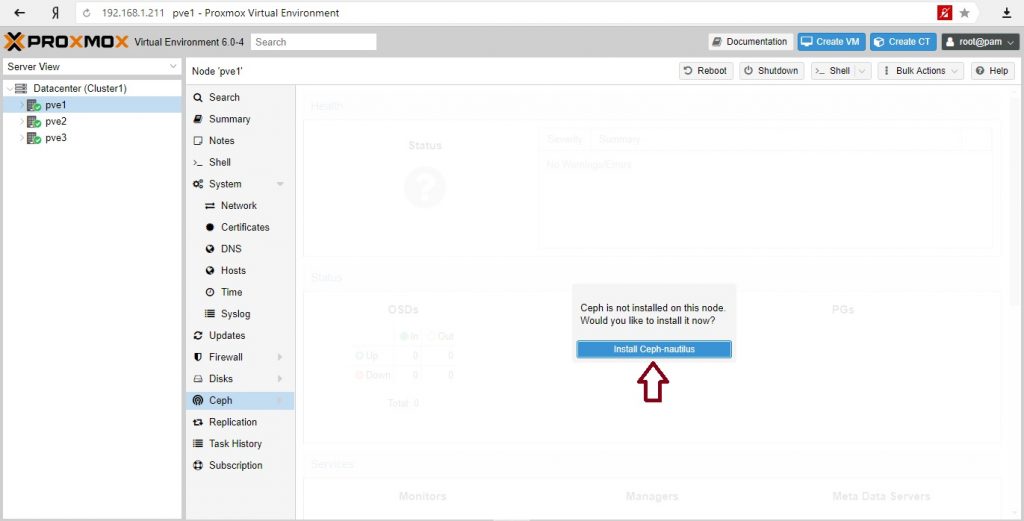
С Proxmox VE вы можете воспользоваться простым в использовании мастером установки Ceph. Щелкните на одном из узлов кластера и перейдите к разделу Ceph в дереве меню. Если пакет еще не установлен, вам будет предложено сделать это сейчас.
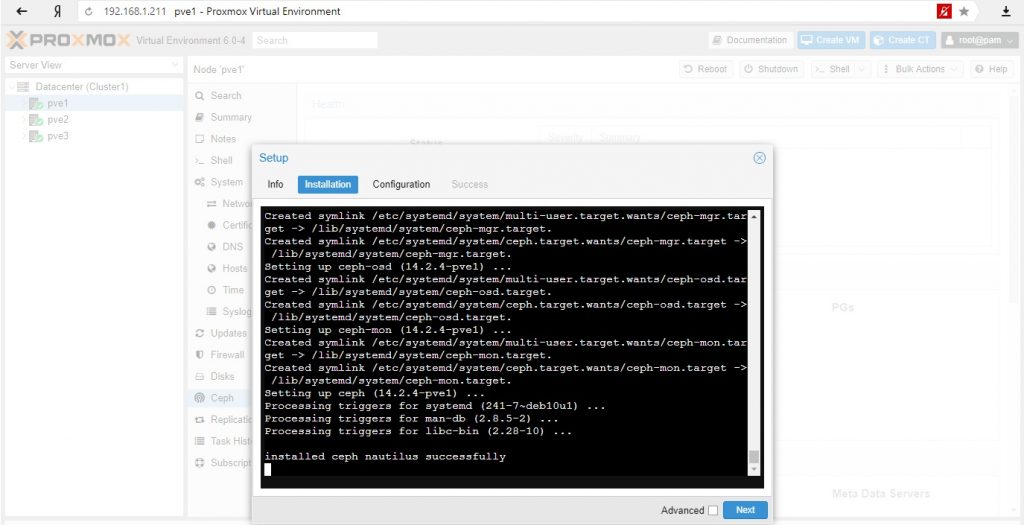
Мастер разделен на различные разделы, каждый из них должен быть успешно завершен, чтобы использовать Ceph. После запуска установки мастер загрузит и установит все необходимые пакеты из репозитория Ceph Proxmox VE.
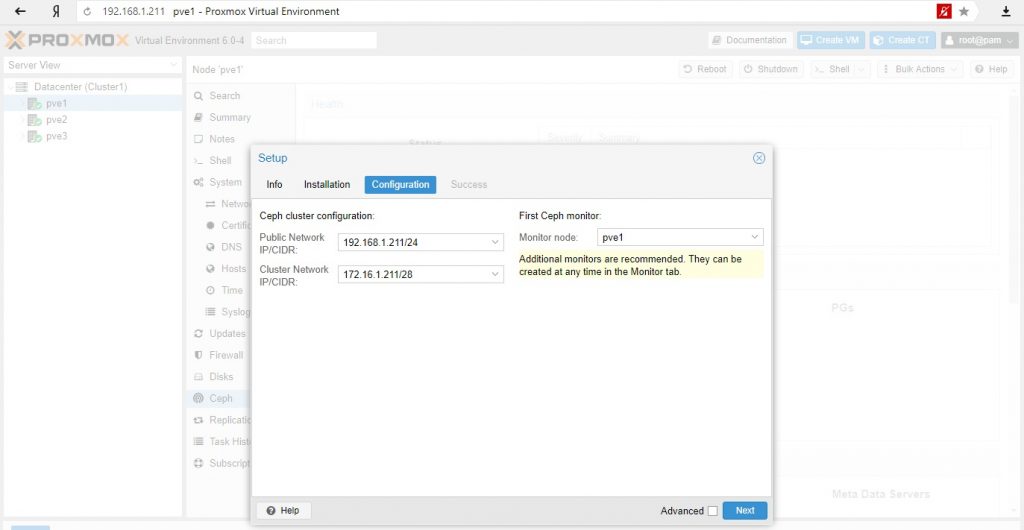
После завершения первого шага, вам нужно будет создать конфигурацию. Этот шаг необходим только один раз для каждого кластера, поскольку эта конфигурация автоматически распространяется среди всех остальных узлов кластера через файловую систему конфигурации кластера Proxmox VE (pmxcfs), глава 7.
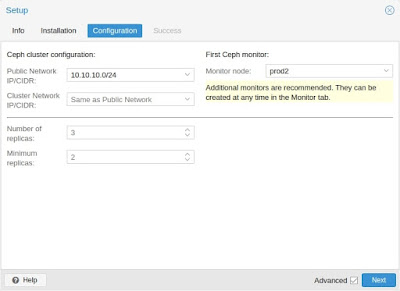
У вас есть еще два варианта, которые считаются расширенными и поэтому должны изменяться только в том случае, если вы являетесь экспертом.
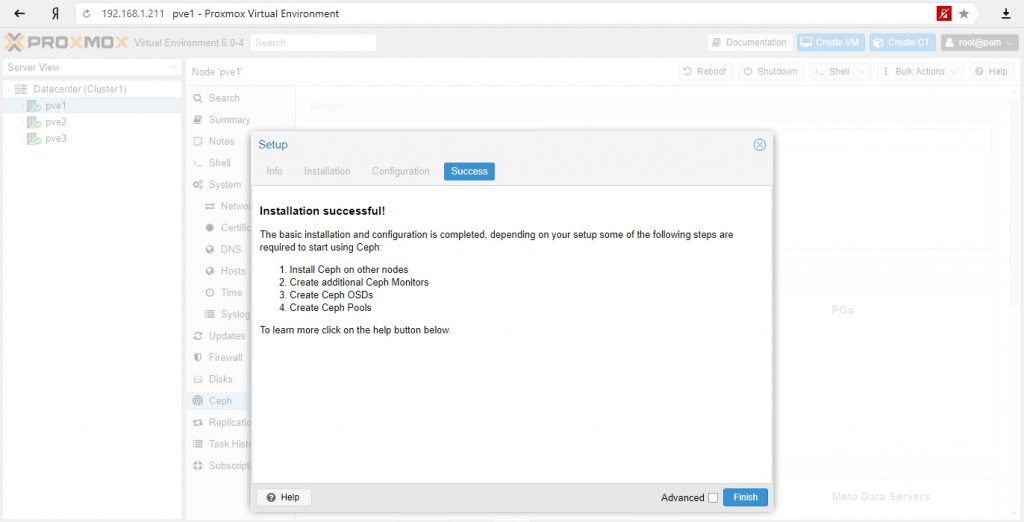
Вот и все, вы должны увидеть сообщение об успешном окончании установки в качестве последнего шага, с инструкциями о дальнейших действиях. Теперь вы готовы начать использовать Ceph, дальше вам нужно будет создать дополнительные мониторы (см. раздел 4.2.5), создать несколько OSD (см. раздел 4.2.7) и по крайней мере один пул (см. раздел 4.2.8).
Остальная часть этой главы будет направлять вас о том, как получить максимальную отдачу от вашего Ceph на базе Proxmox VE, это будет включать в себя вышеупомянутые шаги и другие, такие как CephFS (см. раздел 4.2.11), которая является очень удобным дополнением к вашему новому кластеру Ceph.
Установка пакетов Ceph
Создание начальной конфигурации Ceph

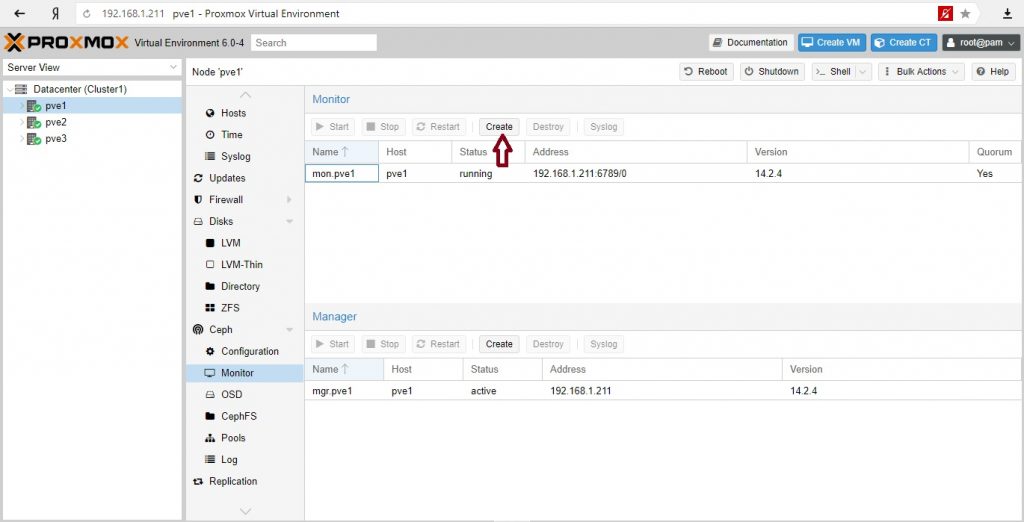
Создание Ceph мониторов
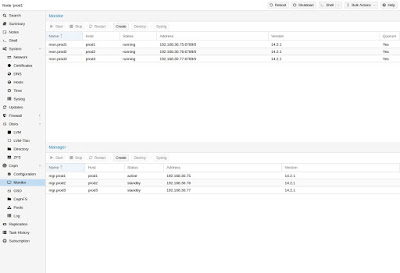
Ceph Monitor (MON) 3 поддерживает главную копию карты кластера. Для высокой доступности необходимо иметь не менее 3 мониторов. Один монитор уже был установлен, если вы использовали мастер установки. Вам не понадобится более 3 мониторов, пока ваш кластер мал до среднего размера, только действительно большие кластеры требуют большего количества.
Создание Ceph Manager
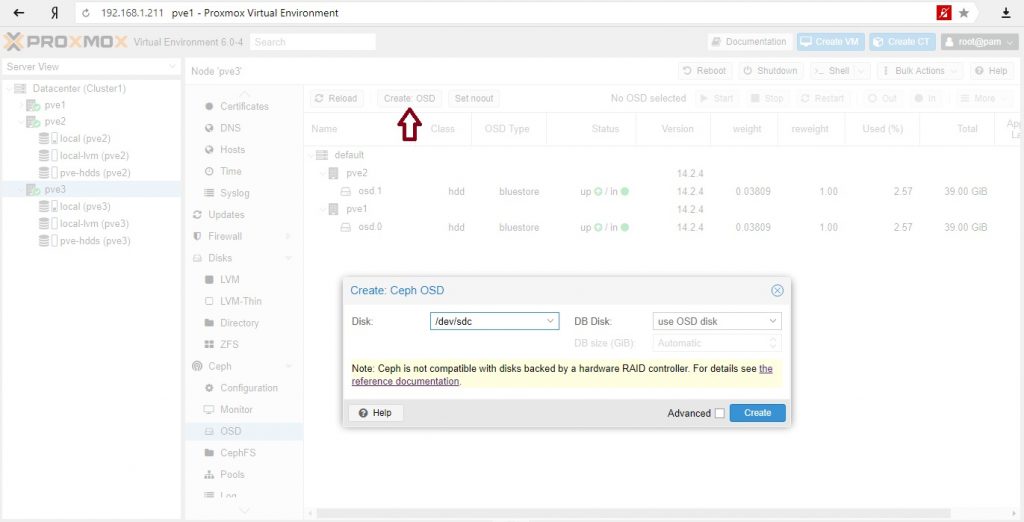
Создание Ceph OSD
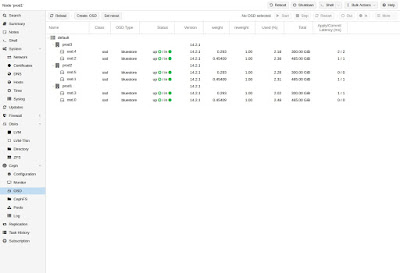
Используя GUI или с помощью коммандной строки следующим образом: Совет Мы рекомендуем размер кластера Ceph, начиная с 12 OSD, равномерно распределенных между вашими, по крайней мере, тремя узлами (4 OSD на каждом узле). Если диск использовался ранее (например, ZFS/RAID/OSD), для удаления таблицы разделов, загрузочного сектора и всех оставшихся OSD должна быть достаточно следующей команды. Внимание! Приведенная выше команда уничтожит данные на диске! Ceph Bluestore
Создание Ceph Пулов

Пул-это логическая группа для хранения объектов. Он содержит группы размещения (PG, pg_num), набор объектов.
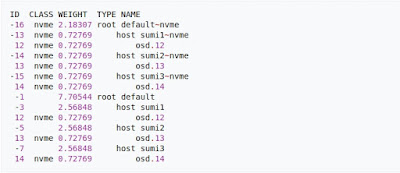
Ceph CRUSH и классы устройств
Классы устройств можно увидеть в выходных данных ceph osd tree. Эти классы представляют свои собственные корневые сегменты, которые можно увидеть с помощью приведенной ниже команды. Пример вывода формы приведенной выше команды:
Ceph Client

Затем можно настроить Proxmox VE для использования таких пулов для хранения образов виртуальных машин или контейнеров. Просто используйте графический интерфейс, чтобы добавить новое хранилище RBD (см. раздел Ceph RADOS Block Devices (RBD) раздел 8.14).
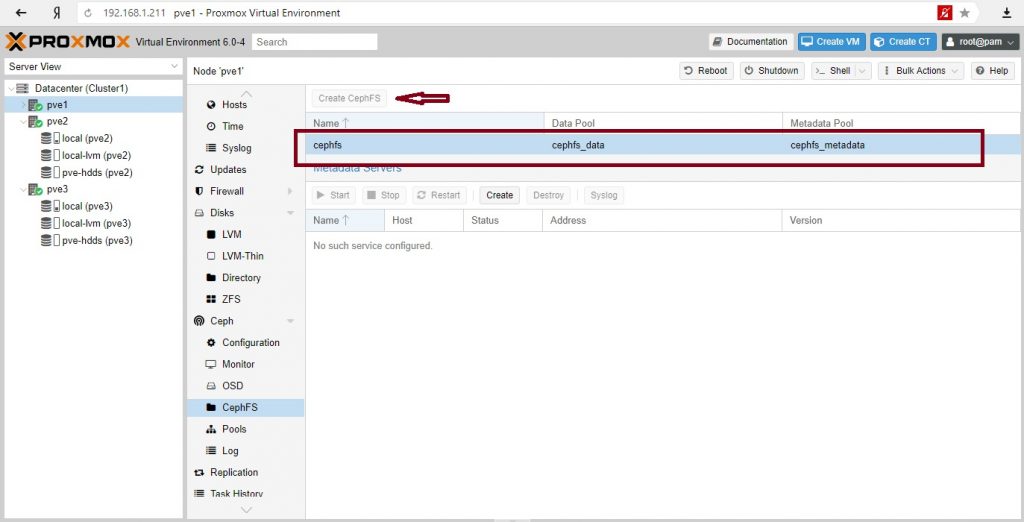
CephFS

Proxmox VE поддерживает оба варианта, используя существующую CephFS в качестве хранилища (см. раздел 8.15) для сохранения резервных копий, ISO-файлов или шаблонов контейнеров и создавая гиперконвергентную CephFS.
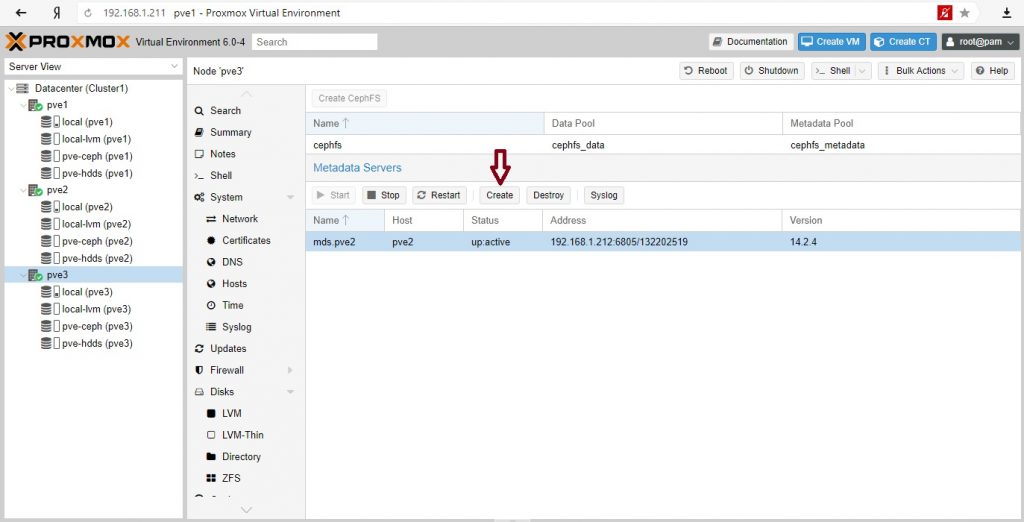
Сервер метаданных (MDS)
Несколько активных MDS
CephFS интегрирована в Proxmox VE и вы можете легко создавать CephFS через веб-интерфейс, интерфейс командной строки или внешний API. Для этого требуются некоторые предварительные условия:
Внимание! Уничтожение CephFS сделает все его данные непригодными для использования, и может быть отменено! Если вы действительно хотите уничтожить существующий CephFS, вам сначала нужно остановить или уничтожить все сервера метаданных (MDS). Вы можете уничтожить их либо через веб-интерфейс или интерфейс командной строки, с помощью: на каждом узле Proxmox VE, где размещается демон MDS.
Затем вы можете удалить (уничтожить) CephFS, выполнив: на одном из узлов, где запущен Ceph. После этого вы можете удалить созданные пулы данных и метаданных, это можно сделать либо через веб-интерфейс пользователя, либо с помощью интерфейса командной строки:
Ceph Мониторинг и устранение неполадок
Хорошей практикой является непрерывный мониторинг работоспособности ceph с самого начала развертывания. Как через набор инструментов самого ceph, так и путем доступа к его статусу через API Proxmox VE.
Нижеследующие команды ceph могут использоваться, чтобы увидеть, является ли кластер исправным (HEALTH_OK), есть ли предупреждения (HEALTH_WARN), или ошибки (HEALTH_ERR). Если кластер находится в нерабочем состоянии, нижеприведенные команды состояния также дадут вам обзор текущих событий и действий.
Глава 5. Установка и настройка Ceph
Содержание
Ceph является высоко масштабируемой, надёжной, распределённой системой хранения
RBD Ceph бесшовно интегрируется с кластерами Proxmox
Ceph может управляться и мониториться через выделенное меню Ceph в GUI Proxmox
Ceph может спокойно обслуживать множество одновременных отказов дисков
По мере роста кластера Ceph в размерах растёт и его производительность
Если вы новичок в Ceph или хотите узнать о нём дополнительные сведения, посетите его официальный сайт по ссылке http://ceph.com/.. Прим. пер.: также рекомендуем наши переводы Книга рецептов Ceph, 2е издание, Изучаем Ceph, 2е издание, Полное руководство Ceph, Книга рецептов Ceph, Изучаем Ceph. >
При сопостоавлении с прочими системами хранения, такими как ZFS, GlusterFS и так далее, Ceph является более сложной системой. Он требует глубоких знаний для надлежащего сопровождения кластера Ceph. Пренебрегая своей сложностью, Ceph также предлагает наивысший уровень избыточности, распространяемый по множеству узлов и это не просто избыточность дисков. В этой главе мы собираемся изучить как устанавливать и настраивать Ceph для работы в кластере Proxmox.
Proxmox VE 5.0 поставляется совместно с Ceph Luminous, который ещё пока не в полной степени готов к промышленному применению < Прим. пер.: это утверждение относится к моменту написания книги, на момент данного перевода Ceph Luminous успешно реализуется в промышленных средах и рекомендуется для применения в них. В первую очередь благодаря уходу от файлового хранения объектов на самом нижнем уровне, что позволяет всецело воспользоваться атомарностью операций и её преимуществами.. > Если ваше имеющееся решение построено на Proxmox VE 4.0, не торопитесь сразу обновлять его. Вместо этого попробуйте вначале Proxmox VE 5.0 в тестовой среде < Прим. пер.: или обратитесь к нам и мы поможем вам перейти на новую версию. >
Компоненты Ceph
Прежде чем погрузиться в его пучину, давайте вначале рассмотрим какие ключевые компоненты составляют сам кластер Ceph. Эти компоненты именно то, что составляет Ceph и важно иметь представление о том, что они из себя представляют.
Физический узел как участник кластера
Физический узел является конкретным работающим серверным оборудованием, которое содержит одну или более компоненту Ceph.
Карты
Карта кластера
Карта кластера является схемой устройств и сегментов (bucket, «корзин»), которые составляют некий кластер Ceph. Ceph применяет иерархию сегментов для определения узлов или местоположения узлов, например, помещение (room), стойка (rack), полка (shelf), хост (host), и так далее. К примеру, давайте допустим, что имеются четыре дисковых устройства применяемых в качестве четырёх OSD в следующей иерархии сегментов:
Карта CRUSH
Для получения дополнительных подробностей посетите следующую ссылку: http://ceph.com/docs/master/rados/operations/crush-map/.
Монитор
MON ( monitor ) Ceph является узлом демона монитора, который содержит карту OSВ, карту PG, карту CRUSH и карту мониторов. Мониторы могут устанавливаться на том же самом узле сервера, что и OSD, или на совершенно отдельной машине. Для поддержания стабильности кластера Ceph настоятельно рекомендуется установка отдельных узлов. Поскольку мониторы отслеживают всё что происходит в кластере, и на самом деле не участвуют в чтении/ записи данных кластера, узел монитора может быть очень скромным в отношении мощности и, следовательно, не затратным. Для достижения состояния жизнеспособности (healthy) кластер Ceph должен иметь установленными, как минимум, три монитора. Состояние жизнеспособности определённого кластера достигается когда в этом кластере всё хорошо и нет никаких предупреждений и ошибок. Отметим, что при последующей интеграции Ceph с Proxmxox совместный с Proxmox узел может применяться в качестве монитора. Начиная с Proxmxox 3.2 имеется возможность установки мониторов Ceph одновременно с узлом Proxmxox, что тем самым исключает потребность в использовании отдельных узлов для мониторов. Мониторы также могут управляться из GUI Proxmxox/
Установка, настройка и эксплуатация Ceph
Цели статьи
Что такое Ceph
Для того, чтобы потестировать ceph, достаточно трех практически любых компьютеров или виртуальных машин. Моя тестовая лаборатория, на которой я буду писать статью, состоит из 4-х виртуальных машин с операционной системой Centos 7 со следующими характеристиками.
| CPU | 2 |
| RAM | 4G |
| DISK | /dev/sda 50G, /dev/sdb 50G |
Это минимальная конфигурация для ceph, с которой стоит начинать тестирование. Из трех машин будет собран кластер ceph, а к четвертой я буду монтировать диски для проверки работоспособности.
Архитектура Ceph
Кластерная система хранения данных ceph состоит из нескольких демонов, каждый из которых обладает своей уникальной функциональностью. Расскажу о них кратко своими словами.
Кластер ceph состоит из пулов для хранения данных. Каждый pool может обладать своими настройками. Пулы состоят из Placement Groups (PG), в которых хранятся объекты с данными, к которым обращаются клиенты.
Аналоги
Вообще говоря, Ceph достаточно уникальное кластерное решение, прямых аналогов которого нет. Но есть некоторые системы, схожие по решаемым проблемам. Основным аналогом Ceph является GlusterFS, которую я рассмотрю ниже отдельно. Так же к аналогам можно отнести следующие кластерные системы хранения данных:
Список не полный. Это только то, что вспомнил я из того, что слышал. Сразу оговорюсь, что перечисленные системы мне практически не знакомы. Список привожу только для того, что, чтобы вам было проще потом самим найти о них информацию и сравнить. Они не являются полными аналогами ceph, но в каких-то вариантах могут подойти больше, нежели он. К примеру, Sheepdog намного проще система и потребности только в хранилище для виртуальных машин может закрывать лучше, чем ceph.
Теперь рассмотрим отдельно GlusterFS.
CephFS vs GlusterFS
Я не буду строить из себя эксперта и пытаться что-то объяснить в том, в чем не разбираюсь. На хабре есть очень подробная статья о сравнении Cephfs с GlusterFS от человека, который использовал обе системы. Если вам интересна тема подобного сравнения, то внимательно прочитайте. Я приведу краткие выводы, которые вынес сам из этой статьи.
Подводя итог статьи автор отмечает, что CephFS более сложное но и более функциональное решение. Я так понял, он отдает предпочтение ему.
Опыт использования
Своего опыта использования Ceph в production у меня нет. Я его хорошо протестировал и понял, что готов к тому, чтобы внедрять и использовать. Так что как и в предыдущем разделе поделюсь сторонними материалами на эту тему, которые изучал сам и они мне показались полезными.
Подготовка настроек
Ну что же, с теоретической частью закончили, начинаем практику. Мы будем устанавливать ceph с помощью официального playbook для ansible. Клонируем к себе репозиторий.
Переключаемся на последнюю стабильную ветку 3.2.
Проверяем зависимости в файле requirements.txt:
=2.6, Вычисление Placement Groups (PG)
Самая большая трудность в вычислении PG это необходимость соблюсти баланс между количеством групп на OSD и их размером. Чем больше PG на одной OSD, тем больше вам надо памяти для хранения информации об их расположении. А чем больше размер самой PG, тем больше данных будет перемещаться при балансировке.
Получается, что если у вас мало PG, они у вас большого размера, надо меньше памяти, но больше трафика уходит на репликацию. А если больше, то все наоборот. Теоретически считается, что для хранения 1 Тб данных в кластере надо 1 Гб оперативной памяти.
Количество PG можно изменять динамически. К примеру, если вы добавили новые OSD, то вы можете увеличить и количество PG в кластере. В последней версии ceph, которая еще не lts, появилась возможность уменьшения Placement Groups.
Установка ceph
Запускаем установку Ceph с помощью playbook ansible.
Если вы используете авторизацию по паролю, то скорее всего получите ошибку подключения к ssh. Я с этим столкнулся. Когда вывел расширенный лог ошибок плейбука, увидел, что ansible подключается по ssh с использованием публичного ключа, который я не задаю. Изменить это можно в конфиге ansible.cfg, который лежит в корне репозитория. Находим там строку:
и удаляем параметр для publickey, чтобы получилось вот так:
После этого заново запускайте развертывание ceph. Оно должно пойти без ошибок. В конце увидите примерно такое сообщение.
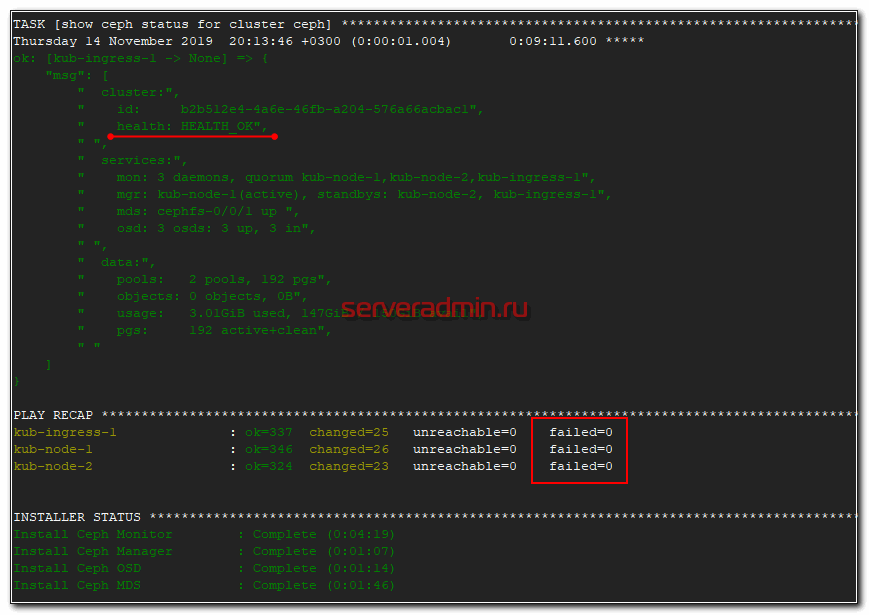
Если будут какие-то ошибки и счетчик failed не будет равен нулю, то разбирайте ошибки, исправляйте их и запускайте роль заново, пока она не закончится без ошибок.
После установки Ceph, можно проверить статус кластера командой, которую нужно выполнить на одной из нод кластера.
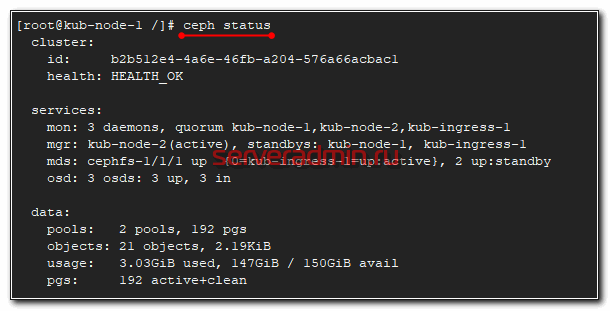
Вы должны увидеть примерно то же самое, что на скриншоте выше. 3 монитора работают в кворуме, друг друга видят, все хорошо.
3 Гб данный ceph занял под свои нужды. Так же нужно учитывать, что доступное пространство в 150 Гб это общее пространство кластера, которое будет расходоваться в зависимости от заданной репликации. Записать 150 Гб данных туда не получится. Если мы запишем 1 Гб данных, они реплицируются на все ноды и будут реально занимать 3 Гб в кластере.
Кластер ceph установлен. Дальше разберем, как с ним работать.
Основные команды
Посмотреть список пулов в кластере:
Статистика использования кластера:
Список всех ключей учетных записей кластера:
Просмотр дерева OSD:
Создание или удаление OSD:
Создание или удаление пула:
Тестирование производительности OSD:
Использование кластера ceph
Для начала давайте посмотрим, какие пулы у нас уже есть в кластере ceph.
Это дефолтные пулы для работы cephfs, которые были созданы в момент установки кластера. Сейчас подробнее на этом остановимся. Ceph представляет для клиента различные варианты доступа к данным:
Подключение Cephfs
Как я уже сказал ранее, для работы cephfs у нас уже есть pool, который можно использовать для хранения данных. Я сейчас подключу его к одной из нод кластера, где у меня есть административный доступ к нему и создам в пуле отдельную директорию, которую мы потом смонтируем на другой сервер.
В данном случае 10.1.4.32 адрес одного из мониторов. Их надо указывать все три, но сейчас я временно подключаю пул просто чтобы создать в нем каталог. Достаточно и одного монитора. Я использую команду:
для того, чтобы получить ключ пользователя admin. С помощью такой конструкции он нигде не засвечивается, а сразу передается команде mount. Проверим, что у нас получилось.
Смонтировали pool. Его размер получился 47 Гб. Напоминаю, что у нас в кластере 3 диска по 50 Гб, фактор репликации 3 и 3 гб заняты под служебные нужды. По факту у нас есть 47 Гб свободного места для использования в кластере ceph. Это место делится поровну между всеми пулами. К примеру, когда у нас появятся rbd диски, они будут делить этот размер вместе с cephfs.
Создаем в cephfs директорию data1, которую будем монтировать к другому серверу.
Теперь нам нужно создать пользователя для доступа к этой директории.
На выходе получите ключ от пользователя. Что я сделал в этой команде:
Если забудете ключ доступа, посмотреть его можно с помощью команды:
Теперь идем на любой другой сервер в сети, который поддерживает работу с cephfs. Это практически все современные дистрибутивы linux. У них поддержка ceph в ядре. Монтируем каталог кластера ceph, указывая все 3 монитора.
Проверяем, что получилось.
Каталог data1 на файловой системе cephfs подключен. Можете попробовать на него что-то записать. Этот же файл вы должны увидеть с любого другого клиента, к которому подключен этот же каталог.
Теперь настроим автомонтирование диска cephfs при старте системы. Для этого надо создать конфиг файл /etc/ceph/data1.secret следующего содержания.
Это просто ключ пользователя data1. Добавляем в /etc/fstab подключение диска при загрузке.
Не забудьте в конце файла fstab сделать переход на новую строку, иначе сервер у вас не загрузится. Теперь проверим, все ли мы сделали правильно. Если у вас уже смонтирован диск, отмонтируйте его и попробуйте автоматически смонтировать на основе записи в fstab.
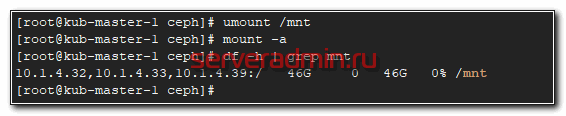
На этом по поводу cephfs все. Можно пользоваться. Переходим к блочным устройствам rbd.
Ceph RBD
Теперь давайте создадим rbd диск в кластере ceph и подключим его к целевому серверу. Для этого идем в консоль на любую ноду кластера. Создаем pool для rbd дисков.
Проверим список пулов кластера.
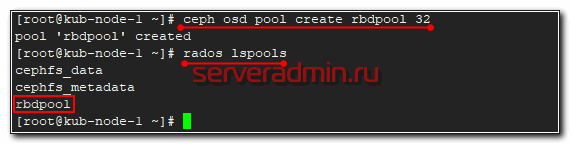
Создаем в этом пуле rbd диск на 10G.
Добавим пользователя с разрешениями на использование этого пула. Делается точно так же, как в случае с cephfs, что мы проделали ранее.
В консоли увидите ключ пользователя rbduser для подключения пула rbdpool.
Перемещаемся на целевой сервер, куда мы будем подключать rbd диск кластера ceph. Для подключения blockdevice нам необходимо поставить программное обеспечение из репозитория ceph-luminous на сервер, где будет использоваться rbd.
Так же запишем на целевой сервер ключ клиента, который имеет доступ к пулу с дисками. Создаем файл /etc/ceph/ceph.client.rbduser.keyring следующего содержания.
Там же создаем конфигурационный файл /etc/ceph/ceph.conf, где нам необходимо указать ip адреса мониторов ceph.
Пробуем подключить блочное устройство.
Скорее всего получите такую же или подобную ошибку. Суть ее в том, что текущее ядро поддерживает не все возможности образа RBD, поэтому их нужно отключить. Как это сделать показано в подсказке. Для отключения нужен администраторский доступ в кластер. Так что идем на любую ноду пула и выполняем там предложенную команду.
Не должно быть никаких ошибок, как и любого вывода после работы команды. Возвращаемся на целевой сервер и пробуем подключить rbd диск еще раз.
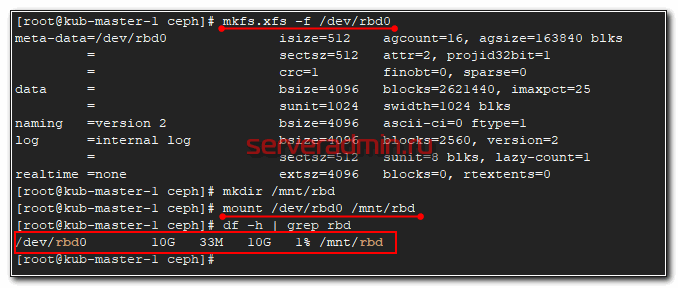
Можно попробовать туда что-то записать и посмотреть на скорость.
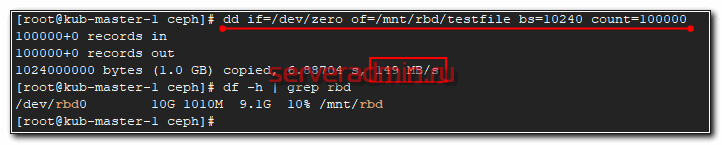
Не знаю, что я измерил 🙂 На самом деле это скорость одиночного sata диска, на котором установлена система сервера, которому я подключил диск. Так понимаю, запись вся ушла в буфер, а потом началась синхронизация по кластеру.
Настроим теперь автоматическое подключение rbd диска при старте системы. Для начала надо настроить mapping диска. Для этого создаем конфиг файл /etc/ceph/rbdmap следующего содержания.
Запускаем скрипт rbdmap и добавляем в автозапуск.
Осталось добавить монтирование блочного устройства rbd в /etc/fstab.
И не забудьте в конце сделать переход на новую строку. После этого перезагрузите сервер и проверьте, что rbd диск кластера ceph нормально подключается.
Проверка надежности и отказоустойчивости
Расскажу, какие проверки отказоустойчивости ceph делал я. Напомню, что у меня кластер состоит всего из трех нод, да еще на sata дисках на двух разных гипервизорах. Многого тут не натестируешь 🙂 Диски собраны в raid1, никакой нагрузки помимо ceph на серверах не было. Я просто выключал одну ноду. При этом в работе кластера не было никаких заметных изменений. С ним можно было нормально работать, писать и читать данные. Самое интересное начиналось, когда я запускал обратно выключенную ноду.
В этот момент запускался ребалансинг кластера и он начинал жутко тормозить. Настолько жутко, что в эти моменты я даже не мог зайти на ноды по ssh или напрямую с консоли, чтобы посмотреть, что именно там тормозит. Виртуальные машины вставали колом. Я пытался их отключать и включать по очереди, но ничего не помогало. В итоге я выключил все 3 ноды и стал включать их по одной. Очевидно, что и нагрузки никакой я не давал, так как кластер был не в состоянии обслуживать внешние запросы.
Включил сначала одну ноду, убедился, что она загрузилась и показывает свой статус. Запустил вторую. Дождался, когда полностью синхронизируются две ноды, потом включил третью. Только после этого все вернулось в нормальное состояние. При этом никаких действий с кластером я не производил. Только следил за статусом. Он сам вернулся в рабочее состояние. Данные все оказались на месте. Меня это приятно удивило, с учетом того, что я жестко выключал зависшие виртуалки несколько раз.
Как я понял, если у вас есть возможность снять с кластера нагрузку, то в момент деградации особых проблем у вас не будет. Это актуально для кластеров с холодными данными, например, под бэкапы или другое долгосрочное хранение. Там можно тормознуть задачи и дождаться ребаланса. Особых проблем с эксплуатацией ceph быть не должно. А вот если у вас идет постоянная работа с кластером, то вам нужно все внимательно проектировать, изучать, планировать, тестировать и т.д. Точно должен быть еще один тестовый кластер и доскональное понимание того, что вы делаете.
Заключение
Надеюсь, моя статья про описание, установку и эксплуатацию ceph была полезна. Постарался объяснять все простым языком для тех, кто как и я, только начинает знакомство с ceph. Мне система очень понравилась именно тем, что ее можно так легко разворачивать и масштабировать. Берешь обычные серверы, раскатываешь ceph, ставишь фактор репликации 3 и не переживаешь за свои данные. Думаю, использовать его под бэкапы, docker registry или некритичное видеонаблюдение.
Переживать начинаешь, когда в кластер идет непрерывная высокая нагрузка. Но тут, как и в любых highload проектах, нет простых решений. Надо во все вникать, во всем разбираться и быть всегда на связи. Меня не привлекают такие перспективы 🙂



