JupyterHub¶
JupyterHub is the best way to serve Jupyter notebook for multiple users. It can be used in a class of students, a corporate data science group or scientific research group. It is a multi-user Hub that spawns, manages, and proxies multiple instances of the single-user Jupyter notebook server.
To make life easier, JupyterHub has distributions. Be sure to take a look at them before continuing with the configuration of the broad original system of JupyterHub. Today, you can find two main cases:
If you need a simple case for a small amount of users (0-100) and single server take a look at The Littlest JupyterHub distribution.
Four subsystems make up JupyterHub:
a Hub (tornado process) that is the heart of JupyterHub
a configurable http proxy (node-http-proxy) that receives the requests from the client’s browser
multiple single-user Jupyter notebook servers (Python/IPython/tornado) that are monitored by Spawners
an authentication class that manages how users can access the system
Besides these central pieces, you can add optional configurations through a config.py file and manage users kernels on an admin panel. A simplification of the whole system can be seen in the figure below:
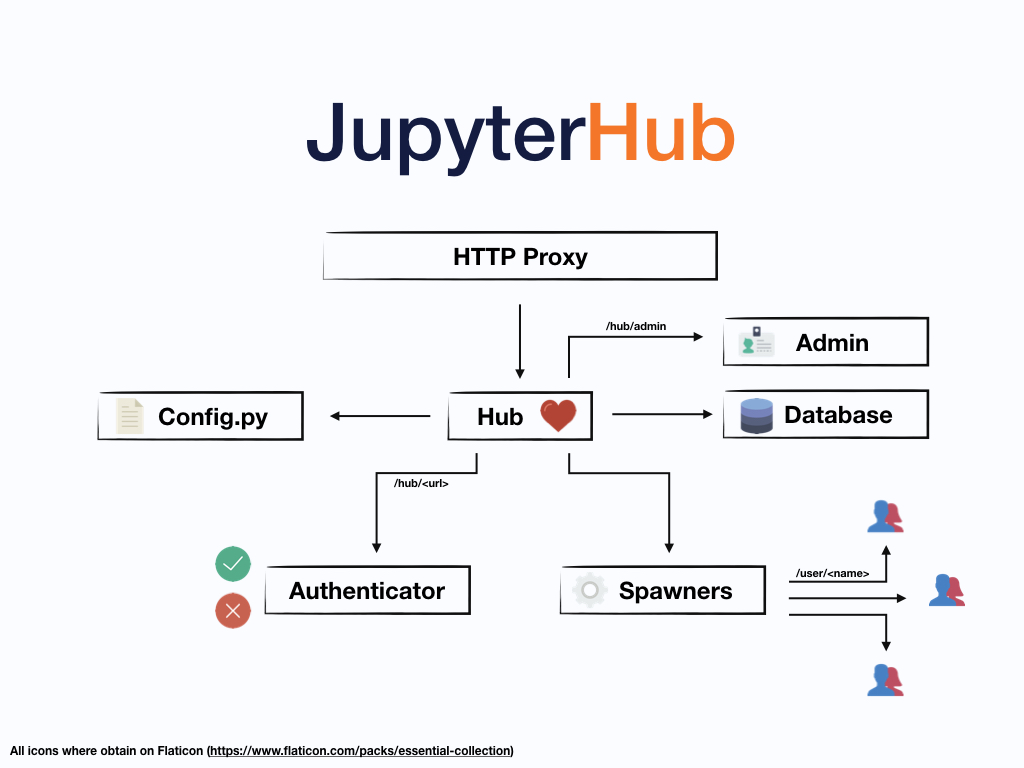
JupyterHub performs the following functions:
The Hub launches a proxy
The proxy forwards all requests to the Hub by default
The Hub handles user login and spawns single-user servers on demand
The Hub configures the proxy to forward URL prefixes to the single-user notebook servers
For convenient administration of the Hub, its users, and services, JupyterHub also provides a REST API.
The JupyterHub team and Project Jupyter value our community, and JupyterHub follows the Jupyter Community Guides.
Contents¶
Distributions¶
A JupyterHub distribution is tailored towards a particular set of use cases. These are generally easier to set up than setting up JupyterHub from scratch, assuming they fit your use case.
The two popular ones are:
Zero to JupyterHub on Kubernetes, for running JupyterHub on top of Kubernetes. This can scale to large number of machines & users.
The Littlest JupyterHub, for an easy to set up & run JupyterHub supporting 1-100 users on a single machine.
Что такое jupiter hub
A multi-user version of the notebook designed for companies, classrooms and research labs
What is JupyterHub?
JupyterHub runs in the cloud or on your own hardware, and makes it possible to serve a pre-configured data science environment to any user in the world. It is customizable and scalable, and is suitable for small and large teams, academic courses, and large-scale infrastructure.
Key features of JupyterHub
The foundational JupyterHub code and technology can be found in the JupyterHub repository. This repository and the JupyterHub documentation contain more information about the internals of JupyterHub, its customization, and its configuration.
Deploy a JupyterHub
The Jupyter Community curates two JupyterHub “distributions” for deploying in the cloud. Follow the links below for more information.
Zero to JupyterHub for Kubernetes deploys JupyterHub on Kubernetes using Docker, allowing it to be scaled and maintained efficiently for large numbers of users. Zero to JupyterHub is a Helm Chart for deploying JupyterHub quickly, as well as a guide to deploying and configuring your JupyterHub on Kubernetes.
The Littlest JupyterHub, a recent and evolving distribution designed for smaller deployments, is a lightweight method to install JupyterHub on a single virtual machine. The Littlest JupyterHub (also known as TLJH), provides a guide with information on creating a VM on several cloud providers, as well as installing and customizing JupyterHub so that users may access it at a public URL.
Join the community
Like all Project Jupyter efforts, JupyterHub is an open-source and community-driven project. We’d love for you to join our community and contribute code, time, comments, or appreciation.
The JupyterHub Gitter Channel is a place where the JupyterHub community discuses developments in the JupyterHub technology, as well as best-practices in deploying and debugging.
Copyright © 2021 Project Jupyter – Last updated Mon, Oct 25, 2021
Особенности Jupyter Notebook, о которых вы (может быть) не слышали
Jupyter Notebook – это крайне удобный инструмент для создания красивых аналитических отчетов, так как он позволяет хранить вместе код, изображения, комментарии, формулы и графики:

Ниже мы расскажем о некоторых фишках, которые делают Jupyter очень крутым. О них можно прочитать и в других местах, но если специально не задаваться этим вопросом, то никогда и не прочитаешь.
Jupyter поддерживает множество языков программирования и может быть легко запущен на любом сервере, необходим только доступ по ssh или http. К тому же это свободное ПО.
Основы
Список хоткеев вы найдете в Help > Keyboard Shortcuts (список периодически дополняется, так что не стесняйтесь заглядывать туда снова).
Отсюда можно получить представление о взаимодействии с блокнотом (notebook). Если вы будете постоянно работать c Jupyter, большинство комбинаций вы быстро выучите.
Экспорт блокнота
Простейший способ — сохранить блокнот в формате IPython Notebook (.ipynb), но так как их используют не все, есть и другие варианты:
Построение графиков
Есть несколько вариантов построения графиков:
Magic-команды
Магические команды (magics) превращают обычный python в магический python. Magic-команды — это ключ к могуществу IPython’а.
Можно управлять переменными среды для вашего блокнота без перезапуска Jupyter-сервера. Некоторые библиотеки (такие, как theano) используют переменные среды, чтобы контролировать поведение, и %env — самый удобный способ.
Выполнение shell-команд
В Notebook можно вызвать любую shell-команду. Это особенно удобно для управления виртуальной средой.
Подавление вывода последней строки
Иногда вывод не нужен, и в этом случае можно или использовать команду pass с новой строки, или поставить точку запятой в конце строки:
вызовет следующее всплывающее окно:
Используйте %run для выполнения кода на Python
Но эта команда может выполнять и другие блокноты из Jupyter! Иногда это очень полезно.
Обратите внимание, что %run — это не то же, что импорт python-модуля.
Загрузит код напрямую в ячейку. Можно выбрать файл локально или из сети.
Если раскомментировать и выполнить код ниже, содержание ячейки заменится на содержание файла.
%store — ленивая передача данных между блокнотами
%who для анализа переменных глобального пространства имен
Тайминг
Если вы хотите замерить время выполнения программы или найти узкое место в коде, на помощь придет IPython.
Профилирование: %prun, %lprun, %mprun
%lprun позволяет профилировать с точностью до строк кода, но, кажется, в последнем релизе Python он не работает, так что в этот раз обойдемся без магии:
Дебаг с помощью %debug
У Jupyter есть собственный интерфейс для ipdb, что позволяет зайти внутрь функции и посмотреть, что в ней происходит.
Это не PyCharm — потребуется время, чтобы освоить, но при необходимости дебага на сервере это может быть единственным вариантом (кроме pdb через терминал).
Немного более простой способ — команда %pdb, которая активирует дебаггер, когда выбрасывается исключение:
Запись формул в LateX
Маркдаун ячейки могут отрисовывать формулы LateX с помощью MathJax.

Маркдаун — важная часть блокнотов, так что не забывайте использовать его выразительные возможности!
Использование разных языков внутри одного блокнота
Если вы соскучились по другим языкам программирования, можете использовать их в Jupyter Notebook:
Анализ Big Data
Существует несколько решений, чтобы запрашивать/обрабатывать большие объемы данных:
Ваши коллеги могут экспериментировать с вашим кодом, ничего не устанавливая
Такие сервисы, как mybinder, предоставляют доступ к Jupiter Notebook со всеми установленными библиотеками, так что пользователь может с полчаса поиграться с вашим кодом, имея под рукой только браузер.
Вы также можете установить вашу собственную системы с помощью jupyterhub, что очень удобно, если вы проводите мини-курс или мастер-класс и вам некогда думать о машинах для студентов.
Написание функций на других языках
Иногда скорости NumPy бывает недостаточно, и мне необходимо написать немного быстрого кода. В принципе, можно собрать нужные функции в динамические библиотеки, а затем написать обертку на Python…
Но гораздо лучше, когда скучная часть работы сделана за нас, правда?
Ведь можно написать нужные функции на Cython или Fortran и использовать их напрямую из кода на Python.
Для начала нужно установить модули
Лично я предпочитаю Fortran, на котором, я считаю, удобно писать функции для обработки большого объема численных данных. Подробнее о его использовании можно почитать здесь.
Должен заметить, что есть и другие способы ускорить ваш код на Python. Примеры можно найти в моем блокноте.
Множественный курсор
С недавнего времени Jupyter поддерживает множественный курсор, такой, как в Sublime или IntelliJ!
Источник: swanintelligence.com/multi-cursor-in-jupyter.html
Расширения Jupyter-contrib
устанавливаются с помощью
Это целое семейство различных расширений, включая, например, jupyter spell-checker и code-formatter, которых по умолчанию в Jupyter нет.
RISE: презентации в Notebook
Расширение, написанное Damian Avila, позволяет демонстрировать блокноты как презентации. Пример такой презентации: bollwyvl.github.io/live_reveal/#/7
Это может пригодиться, если вы обучаете использованию какой-либо библиотеки.
Система вывода Jupyter
Блокноты отображаются в HTML, и вывод ячейки тоже может быть в формате HTML, так что вы можете выводить все, что душе угодно: видео, аудио, изображения.
В этом примере я просматриваю содержимое директории с картинками в моем репозитории и отображаю первые пять из них.
Я мог бы получить тот же список bash-командой,
потому что magic-команды и bash-вызовы возвращают переменные Python:
Повторное подключение к ядру
Давным давно, если вы запускали какой-нибудь долгий процесс и в какой-то момент подключение к серверу IPython прерывалось, вы полностью теряли возможность отслеживать процесс вычислений (если только вы не записывали эти данные в файл). Приходилось или прерывать работу ядра с риском потерять некоторые результаты, или ждать окончания процесса, не имея представления о том, что в данный момент происходит.
Теперь опция Reconnect to kernel позволяет заново подключиться к работающему ядру, не прерывая вычислений, и увидеть последний вывод (хотя какая-то часть вывода все же будет потеряна).
Пишите ваши посты в Notebook
такие, как этот. Используйте nbconvert, чтобы экспортировать в HTML.
Что позволено Jupyter?
Наша история началась с, казалось бы, несложной задачи. Нужно было настроить аналитические инструменты для data science специалистов и просто аналитиков данных. С таким заданием к нам обратились коллеги из подразделений розничных рисков и CRM, где исторически высока концентрация data science-специалистов. У заказчиков было простое желание — писать код на Python, импортировать продвинутые библиотеки (xgboost, pytorch, tensorflow и пр.) и запускать алгоритмы на данных, поднятых с hdfs-кластера.
Вроде бы все просто и понятно. Но подводных камней оказалось так много, что мы решили написать об этом пост и выложить готовое решение на GitHub.
Для начала немного подробностей про исходную инфраструктуру:
Казалось бы, все просто: надо взять и настроить связку Python+Anaconda+Spark. Установить Jupyter Hub на сервере приложений, осуществить интеграцию с LDAP, подключить Spark или подконнектиться к данным в hdfs каким-либо другим способом и вперед – строить модели!
Если углубиться во все исходные данные и требования, то вот более подробный список:
Описание решения
Запуск в Docker + интеграция с кластером Cloudera
Здесь нет ничего необычного. В контейнере установлены JupyterHub и клиенты продуктов Cloudera (как – см. ниже), а конфигурационные файлы подмонтированы с хост-машины:
Интеграция с Active Directory
Для интеграции с Active Directory / Kerberos железных и не очень хостов стандартом в нашей компании является продукт PBIS Open. Технически данный продукт представляет собой набор сервисов, общающихся с Active Directory, с которыми, в свою очередь, через unix domain сокеты работают клиенты. Данный продукт интегрируется с Linux PAM и NSS.
Мы применили стандартный для Docker прием – unix domain сокеты сервисов хоста были примонтированы в контейнер (сокеты были найдены опытным путем нехитрыми манипуляциями командой lsof):
В свою очередь, внутрь контейнера устанавливаются пакеты PBIS, но без выполнения postinstall секции. Так мы ставим только исполняемые файлы и библиотеки, но не запускаем сервисы внутри контейнера — для нас это лишнее. Команды интеграции с PAM и NSS Linux запускаются вручную.
Получается, что клиенты PBIS контейнера общаются с сервисами PBIS хоста. В JupyterHub применяется PAM-аутентификатор, и при правильно настроенном PBIS на хосте все работает «из коробки».
Чтобы не пускать в JupyterHub всех пользователей из AD, можно воспользоваться настройкой, ограничивающей пользователей конкретными AD группами.
Прозрачная аутентификация в Hadoop и Spark
При логине в JupyterHub PBIS кэширует Kerberos-тикет пользователя в определенном файле в каталоге /tmp. Для прозрачной аутентификации таким образом достаточно примонтировать каталог /tmp хоста в контейнер и установить переменную KRB5CCNAME в нужное значение (это делается в нашем классе аутентификатора).
Благодаря приведенному выше коду пользователь JupyterHub может выполнять команды hdfs из терминала Jupyter и запускать Spark job’ы без дополнительных действий для аутентификации. Монтировать весь каталог /tmp хоста в контейнер небезопасно — эту проблему мы осознаем, но ее решение пока еще в проработке.
Версии Python 2 и 3
Здесь, казалось бы, все просто: нужно поставить необходимые версии Python и сынтегрировать их с Jupyter, создав необходимые Kernel. Этот вопрос уже много где освещен. Для управления окружениями Python используется Conda. Почему вся простота лишь кажущаяся, будет ясно из следующего раздела. Пример Kernel для Python 3.6 (этого файла нет в git – все kernel-файлы генерируются кодом):
Spark 1 и 2
Для интеграции с клиентами SPARK также необходимо создать Kernel’и. Пример Kernel для Python 3.6 и SPARK 2.
Сразу отметим, что требование иметь поддержку Spark 1 сложилось исторически. Однако, возможно, кто-то столкнется с похожими ограничениями — нельзя, например, установить Spark 2 в кластер. Поэтому опишем здесь подводные камни, которые встретились нам на пути реализации.
Во-первых, Spark 1.6.1 не работает с Python 3.6. Что интересно, в CDH 5.12.1 это исправили, а вот в 5.15.1 — почему-то нет). Сначала мы хотели решить эту проблему, просто применив соответствующий патч. Однако в дальнейшем от этой идеи пришлось отказаться, так как данный подход требует установки модифицированного Spark в кластер, что для нас оказалось неприемлемо. Выход был найден в создании отдельного окружения Conda с Python 3.5.
Вторая проблема не позволяет Spark 1 работать внутри Docker. Драйвер Spark открывает определенный порт, по которому с драйвером устанавливает соединение Worker — для этого драйвер посылает ему свой IP-адрес. В случае с Docker Worker пытается соединиться с драйвером по IP контейнера и при использовании network=bridge у него это вполне естественным образом не получается.
Очевидное решение — посылать не IP контейнера, а IP хоста, что и было реализовано в Spark 2 добавлением соответствующей конфигурационной настройки. Этот патч был творчески переработан и применен к Spark 1. Модифицированный таким образом Spark не нужно ставить на хосты кластера, поэтому проблемы, подобной несовместимости с Python 3.6, не возникает.
Вне зависимости от версии Spark, для его работоспособности необходимо иметь в кластере те же самые версии Python, что и в контейнере. Для установки Anaconda напрямую в обход Cloudera Manager нам пришлось научиться делать две вещи:
Сборка parcel Anaconda
Это оказалось довольно простой задачей. Все, что нужно, это:
Установка parcel в Docker
Данная практика оказалась полезна по двум причинам:
Ограничение ресурсов хост-машины
Для управления ресурсами хост-машины используется сочетание DockerSpawner — компонента, запускающего Jupyter конечных пользователей в отдельном Docker-контейнере — и cgroups — механизма управления ресурсами в Linux. DockerSpawner использует Docker API, который позволяет задавать родительскую cgroup для контейнера. В штатном DockerSpawner такой возможности нет, поэтому нами был написан простой код, позволяющий задавать соответствие между сущностями AD и parent cgroup в конфигурации.
Также была внесена небольшая модификация, которая запускает Jupyter из того же образа, из которого запущен JupyterHub. Таким образом нет необходимости использовать более одного образа.
Что именно запускать в контейнере, Jupyter или JupyterHub, определяется в стартовом скрипте по переменным окружения:
Возможность стартовать Docker-контейнеры Jupyter из Docker-контейнера JupyterHub достигается монтированием сокета демона Docker в контейнер JupyterHub.
В будущем планируется отказаться от этого решения в пользу, например, ssh.
При использовании DockerSpawner совместно со Spark возникает еще одна проблема: драйвер Spark открывает случайные порты, по которым потом устанавливается соединение извне Worker’ами. Мы можем управлять диапазоном номеров портов, из которых выбираются случайные, задавая эти диапазоны в конфигурации Spark. Однако данные диапазоны должны быть разными для разных пользователей, так как мы не можем запускать контейнеры Jupyter с одними и теми же опубликованными портами. Для решения этой задачи был написан код, который просто генерирует диапазоны портов по id пользователя из БД JupyterHub и запускает Docker-контейнер и Spark с соответствующей конфигурацией:
Недостатком такого решения является то, что при перезапуске контейнера с JupyterHub все перестает работать по причине потери БД. Поэтому при перезапуске JupyterHub для, например, изменения конфигурации мы не трогаем сам контейнер, а перезапускаем только процесс JupyterHub внутри него.
Сами cgroups создаются стандартными средствами Linux, соответствие между сущностями AD и cgroups в конфигурации выглядит так.
Код в git
Наше решение есть в публичном доступе на GitHub: https://github.com/DS-AI/dsai/ (DSAI – Data Science and Artificial Intelligence). Весь код разложен по каталогам с порядковыми номерами — код из каждого следующего каталога может использовать артефакты из предыдущего. Результатом работы кода из последнего каталога будет Docker-образ.
Каждый каталог содержит файлы:
Для сборки мы используем машину с Linux RedHat 7.4, Docker 17.05.0-ce. На машине 8 ядер, 32Гб RAM и 250ГБ дискового пространства. Настоятельно не рекомендуется использовать для сборки хост с худшими параметрами по RAM и HDD.
Вот справка по использованным названиям:
Еще один недостаток – сборка parcel невоспроизводима. Так как библиотеки постоянно обновляются, то повторение сборки может дать результат отличный от предыдущего.
Руководство по Jupyter Notebook для начинающих
Jupyter Notebook — это мощный инструмент для разработки и представления проектов Data Science в интерактивном виде. Он объединяет код и вывод все в виде одного документа, содержащего текст, математические уравнения и визуализации.
Такой пошаговый подход обеспечивает быстрый, последовательный процесс разработки, поскольку вывод для каждого блока показывается сразу же. Именно поэтому инструмент стал настолько популярным в среде Data Science за последнее время. Большая часть Kaggle Kernels (работы участников конкурсов на платформе Kaggle) сегодня созданы с помощью Jupyter Notebook.
Этот материал предназначен для новичков, которые только знакомятся с Jupyter Notebook, и охватывает все этапы работы с ним: установку, азы использования и процесс создания интерактивного проекта Data Science.
Настройка Jupyter Notebook
Чтобы начать работать с Jupyter Notebook, библиотеку Jupyter необходимо установить для Python. Проще всего это сделать с помощью pip:
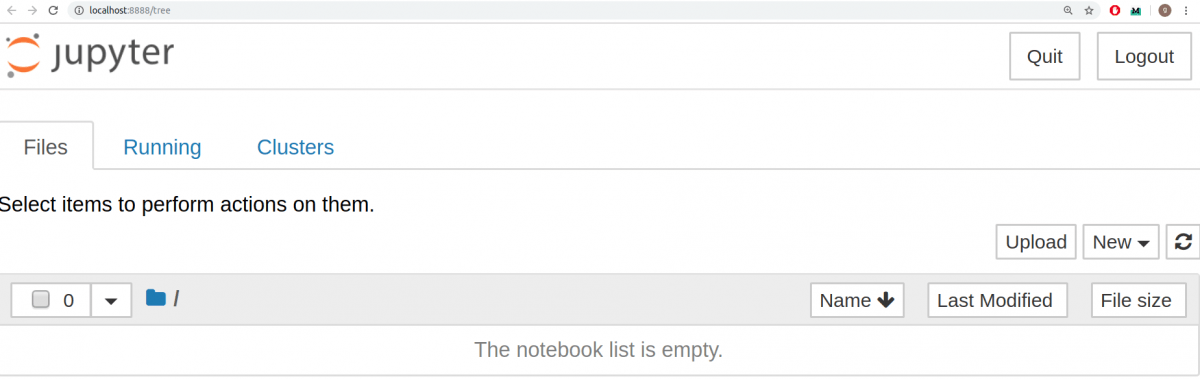
Теперь нужно разобраться с тем, как пользоваться библиотекой. С помощью команды cd в командной строке (в Linux и Mac) в первую очередь нужно переместиться в папку, в которой вы планируете работать. Затем запустите Jupyter с помощью следующей команды:
Это запустит сервер Jupyter, а браузер откроет новую вкладку со следующим URL: https://localhost:8888/tree. Она будет выглядеть приблизительно вот так:
Отлично. Сервер Jupyter работает. Теперь пришло время создать первый notebook и заполнять его кодом.
Основы Jupyter Notebook
Для создания notebook выберите «New» в верхнем меню, а потом «Python 3». Теперь страница в браузере будет выглядеть вот так:
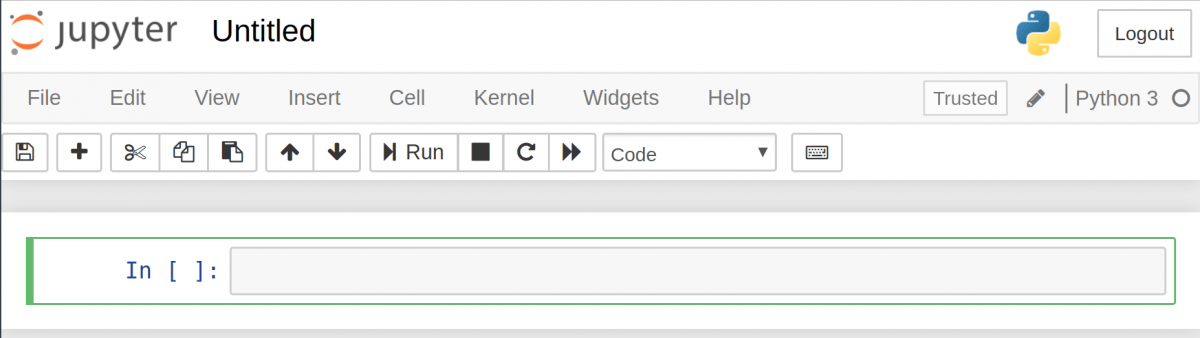
Теперь напишем какой-нибудь код!
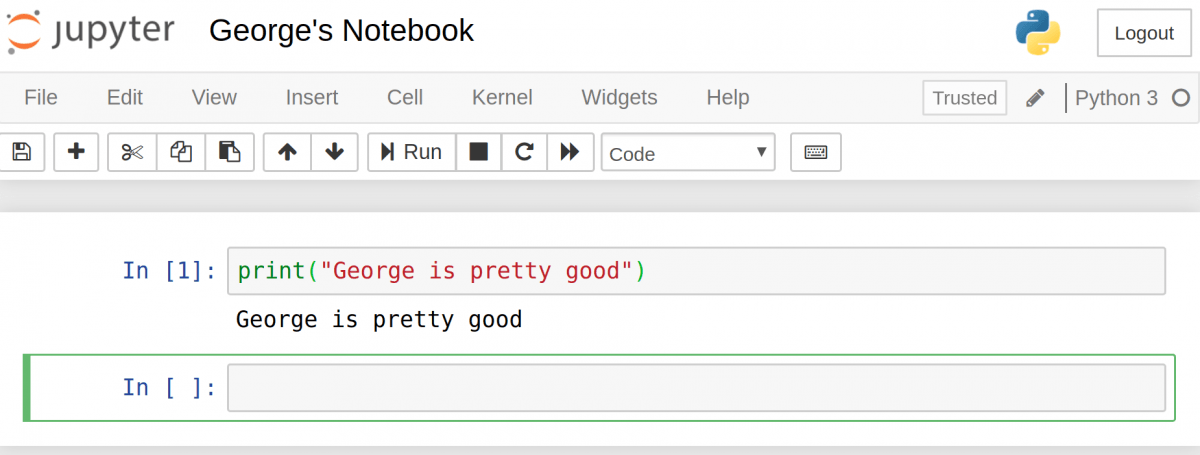
Вывод должен отобразиться прямо в notebook. Это и позволяет заниматься программированием в интерактивном формате, имея возможность отслеживать вывод каждого шага.
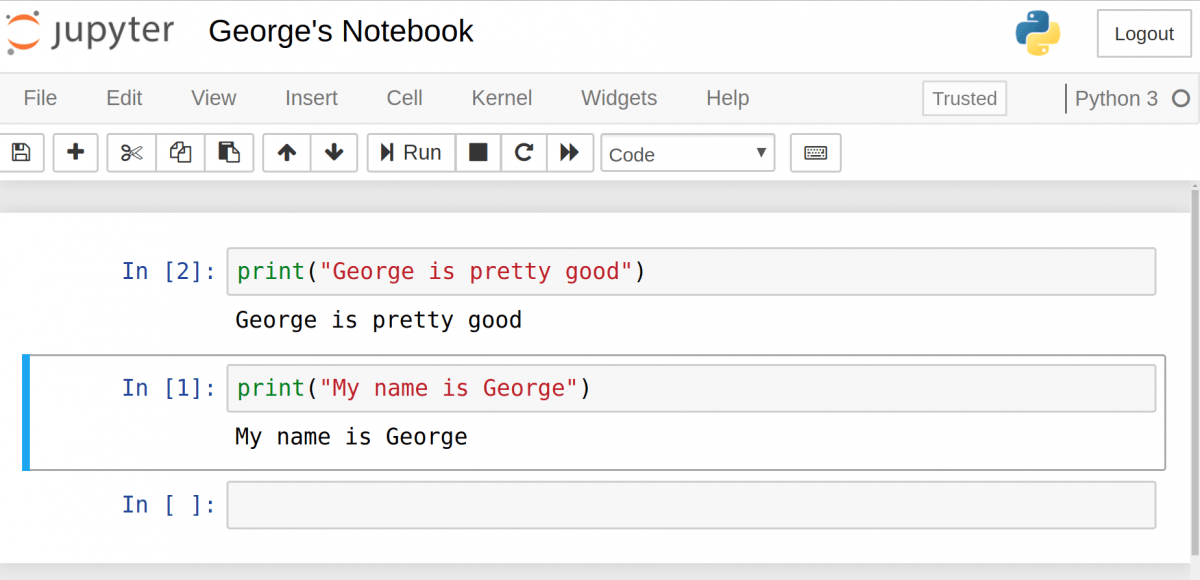
Если есть несколько ячеек, то между ними можно делиться переменными и импортами. Это позволяет проще разбивать весь код на связанные блоки, не создавая переменную каждый раз. Главное убедиться в запуске ячеек в правильном порядке, чтобы переменные не использовались до того, как были созданы.
Добавление описания к notebook
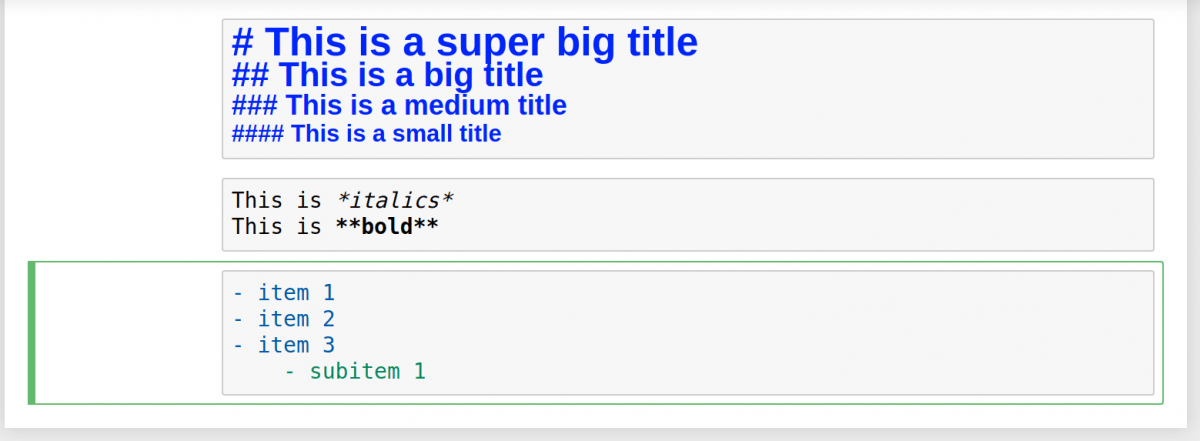
В Jupyter Notebook есть несколько инструментов, используемых для добавления описания. С их помощью можно не только оставлять комментарии, но также добавлять заголовки, списки и форматировать текст. Это делается с помощью Markdown.
Первым делом нужно поменять тип ячейки. Нажмите на выпадающее меню с текстом «Code» и выберите «Markdown». Это поменяет тип ячейки.
Интерактивная наука о данных
Соорудим простой пример проекта Data Science. Этот notebook и код взяты из реального проекта.

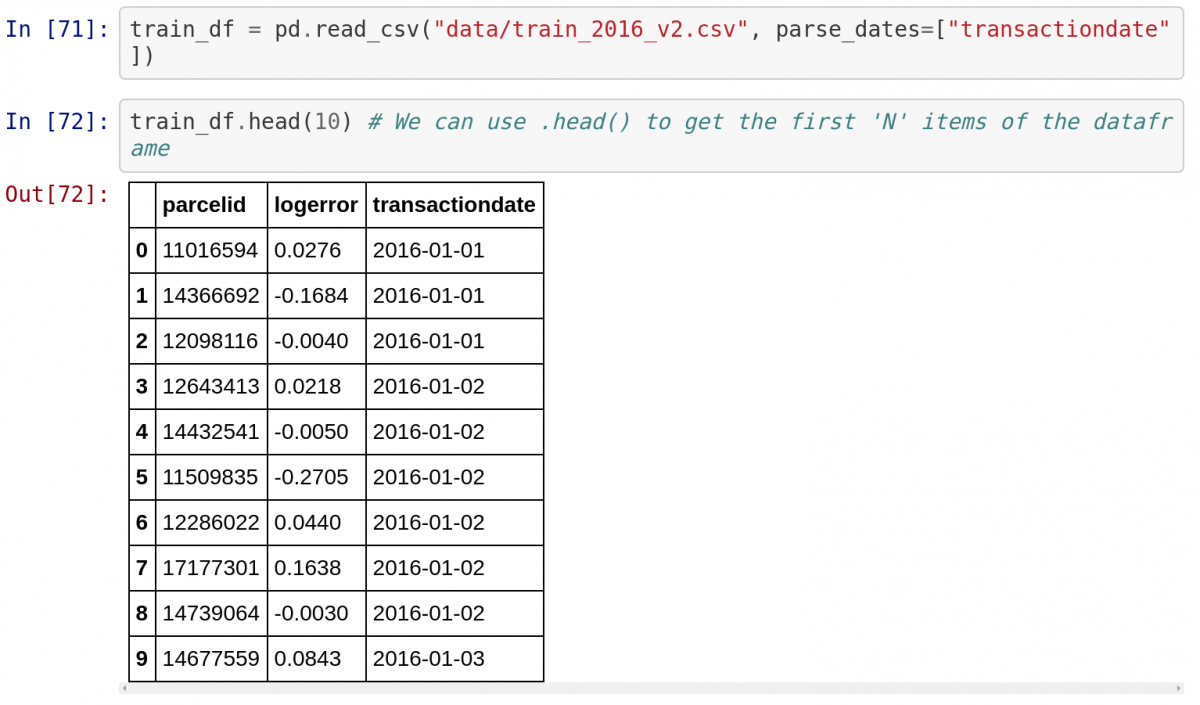
Также обратите внимание на то, как переменные из предыдущих ячеек, содержащие данные из CSV-файла, используются в последующих ячейках в том случае, если по отношению к первым была нажата кнопка «Run».
Это простейший способ создания интерактивного проекта Data Science!
На сервере Jupyter есть несколько меню, с помощью которых от проекта можно получить максимум. С их помощью можно взаимодействовать с notebook, читать документацию популярных библиотек Python и экспортировать проект для последующей демонстрации.
Редактировать (Edit): используется, чтобы вырезать, копировать и вставлять код. Здесь же можно поменять порядок ячеек, что понадобится для демонстрации проекта.
Вставить (Insert): для добавления ячеек перед или после выбранной.
Ячейка (Cell): отсюда можно запускать ячейки в определенном порядке или менять их тип.
Помощь (Help): в этом разделе можно получить доступ к важной документации. Здесь же упоминаются горячие клавиши для ускорения процесса работы. Наконец, тут можно найти ссылки на документацию для самых важных библиотек Python: Numpy, Scipy, Matplotlib и Pandas.



