Построение кластеров Kubernetes средствами самого Kubernetes

Думаете, я сошел с ума? Я уже сталкивался с такой реакцией, когда впервые предложил развертывать кластеры Kubernetes с помощью Kubernetes.
Но я убежден, что для автоматизации облачной инфраструктуры нет более эффективного инструмента, чем сам Kubernetes. С помощью одного центрального кластера K8s мы можем создать сотни других подконтрольных кластеров K8s. В этой статье я покажу, как это делается.
Примечание. SAP Concur использует AWS EKS, но рассматриваемые здесь концепции также применимы к Google GKE, Azure AKS и любым другим реализациям Kubernetes от облачных провайдеров.
Готовность к эксплуатации в рабочей среде
Создать кластер Kubernetes у любого из распространенных облачных провайдеров стало проще простого. Например, в AWS EKS кластер поднимается одной командой:
$ eksctl create cluster
Совсем другое дело, если нужно получить кластер Kubernetes, готовый к эксплуатации в рабочей среде — «production-ready» Понятие «production-ready» может толковаться по-разному, но в SAP Concur используются следующие четыре этапа для создания и предоставления кластеров Kubernetes, готовых к эксплуатации в рабочей среде.
Четыре этапа сборки
Предварительное тестирование. Перечень простых тестов целевой среды AWS, которые проверяют соответствие всем необходимым требованиям до начала сборки кластера. Например, проверяются доступные IP-адреса в подсетях, экспортируемые параметры для AWS, параметры SSM или другие переменные.
Уровень управления EKS и группа узлов. Непосредственно сборка кластера AWS EKS с подключением рабочих узлов.
Установка дополнений. Добавим в кластер любимую приправу. 🙂 По желанию можно установить такие дополнения, как Istio, Logging Integration, Autoscaler и пр.
Валидация кластера. На этом этапе мы проверяем кластер (основные компоненты EKS и дополнения) с функциональной точки зрения перед его передачей в эксплуатацию. Чем больше тестов вы напишете, тем крепче будете спать. (Особенно, если в техподдержке именно вы на дежурстве!)
Склеиваем все вместе
Четыре этапа сборки включают в себя разные инструменты и методы (мы вернемся к ним позже). Нам нужен был универсальный инструмент для всех этапов, который склеил бы все вместе, поддерживал последовательное и параллельное выполнение, был событийно-ориентированным и, желательно, визуализировал сборку.
В результате мы нашли семейство решений Argo, в частности инструменты Argo Events и Argo Workflows. Они оба запускаются в Kubernetes как CRD и полагаются на декларативную концепцию YAML, как и множество других развертываний Kubernetes.
У нас получилась идеальная комбинация: императивная оркестрация и декларативная автоматизация
Кластер K8s, готовый к эксплуатации в рабочей среде. Создан с помощью Argo Workflows
Поэтапная реализация процесса в Argo Workflows
Argo Workflows — это движок рабочих процессов с открытым кодом и нативной поддержкой контейнеров, предназначенный для оркестрации параллельных заданий в среде Kubernetes. Argo Workflows реализован как Kubernetes CRD.
Примечание. Если вы знакомы с K8s YAML, обещаю, что вы разберетесь.
Давайте посмотрим, как все эти четыре этапа сборки могут выглядеть в Argo Workflows.
1. Предварительное тестирование
Мы пишем тесты на фреймворке BATS. Написать предварительный тест в BATS очень просто:
Параллельный запуск приведенного выше тестового файла BATS ( avail-ip-addresses.bats ) вместе с тремя другими вымышленными тестами BATS через Argo Workflows выглядит следующим образом:
2. Уровень управления EKS и группа узлов
3. Установка дополнений
4. Валидация кластера
Для валидации дополнений мы применяем BATS-библиотеку DETIK, которая заметно упрощает написание тестов для K8s.
Только представьте, сколько еще можно сюда подключить тестов. Нужны тесты Sonobuoy, Popeye или Fairwinds Polaris? Просто подключите их через Argo Workflows!
Но мы еще не прощаемся — самое интересное я оставил напоследок.
Шаблоны рабочих процессов
Argo Workflows поддерживает многоразовые шаблоны рабочих процессов (WorkflowTemplates). Каждый из четырех этапов сборки представляет собой такой шаблон. По сути, мы получили сборочные элементы, которые можно произвольно комбинировать друг с другом. Все этапы сборки можно выполнять по порядку через главный рабочий процесс (как в примере выше) или можно запускать их независимо друг от друга. Такая гибкость стала возможной благодаря Argo Events.
Argo Events
Argo Events — это событийно-ориентированный фреймворк для Kubernetes, который позволяет инициировать объекты K8s, Argo Workflows, бессерверные рабочие нагрузки и другие операции на основе различных триггеров, таких как веб-хуки, события в S3, расписания, очереди сообщений, Google Cloud Pub/Sub, SNS, SQS и пр.
Сборка кластера запускается посредством API-вызова (Argo Events) с использованием полезной нагрузки из JSON. Кроме того, каждый из четырех этапов сборки (WorkflowTemplates) имеет собственную конечную точку API. Операторы Kubernetes (то есть люди) получают явные преимущества:
Не уверены, в каком состоянии находится облачная среда? Вызывайте API предварительных тестов.
Хотите собрать «голый» кластер EKS? Вызывайте API eks-core (control-plane и nodegroup).
Хотите установить или переустановить дополнения в существующем кластере EKS? Вызывайте API дополнений.
Кластер начал чудить и вам нужно быстро его протестировать? Вызывайте API тестирования.
Возможности Argo
Решения Argo Events и Argo Workflows предлагают широкий функционал прямо «из коробки», не нагружая вас лишней работой.
Вот семь самых востребованных функций:
Повторные попытки (см. выделенные красным предварительные тесты и тесты валидации на рисунках выше: они завершались сбоем, но Argo повторял их до успешного прохождения)
Шаблоны рабочих процессов
Параметры сенсоров событий
Заключение
Мы подружили множество различных инструментов и смогли через них императивно задать желаемое состояние инфраструктуры. Мы получили гибкое, бескомпромиссное и быстрое в реализации решение на основе Argo Events и Workflows. В планах — приспособить эти инструменты под другие задачи автоматизации. Возможности безграничны.
Перевод материала подготовлен в рамках курса «Инфраструктурная платформа на основе Kubernetes». Всех желающих приглашаем на двухдневный онлайн-интенсив «Примитивы, контроллеры и модели безопасности k8s». На нем будет обзор и практика по основным примитивам и контроллерам к8с. Рассмотрим, чем отличаются и в каких случаях используются. Регистрация здесь
Проектирование Kubernetes-кластеров: сколько их должно быть?
Прим. перев.: этот материал от образовательного проекта learnk8s — ответ на популярный вопрос при проектировании инфраструктуры на базе Kubernetes. Надеемся, что достаточно развёрнутые описания плюсов и минусов каждого из вариантов помогут сделать оптимальный выбор и для вашего проекта.
TL;DR: один и тот же набор рабочих нагрузок можно запустить на нескольких крупных кластерах (на каждый кластер будет приходиться большое число workload’ов) или на множестве мелких (с малым числом нагрузок в каждом кластере).
Ниже приведена таблица, в которой оцениваются плюсы и минусы каждого подхода:
При использовании Kubernetes в качестве платформы для эксплуатации приложений часто возникают несколько фундаментальных вопросов о тонкостях настройки кластеров:
Постановка вопроса
Как создатель ПО, вы скорее всего параллельно разрабатываете и эксплуатируете множество приложений.
Кроме того, множество экземпляров этих приложений наверняка запускаются в различных окружениях — к примеру, это могут быть dev, test и prod.
В результате получается целая матрица из приложений и окружений:
Приложения и окружения
В приведенном выше примере представлены 3 приложения и 3 окружения, что в итоге дает 9 возможных вариантов.
Каждый экземпляр приложения представляет собой самодостаточную deployment-единицу, с которой можно работать независимо от других.
Обратите внимание, что экземпляр приложения может состоять из множества компонентов, таких как фронтенд, бэкенд, база данных и т.д. В случае микросервисного приложения экземпляр будет включать в себя все микросервисы.
В результате у пользователей Kubernetes возникают несколько вопросов:
Вот некоторые из возможных путей:
От нескольких больших кластеров (слева) до множества маленьких (справа)
В общем случае считается, что один кластер «больше» другого если у него больше сумма узлов и pod’ов. Например, кластер с 10-ю узлами и 100 pod’ами больше кластера с 1-м узлом и 10-ю pod’ами.
Что ж, давайте начнем!
1. Один большой общий кластер
Первый вариант — разместить все рабочие нагрузки в одном кластере:
Один большой кластер
В рамках этого подхода кластер используется как универсальная инфраструктурная платформа — все необходимое вы просто разворачиваете в существующем кластере Kubernetes.
Namespace’ы Kubernetes позволяют логически отделить части кластера друг от друга, так что для каждого экземпляра приложения можно использовать свое пространство имен.
Давайте рассмотрим плюсы и минусы этого подхода.
+ Эффективное использование ресурсов
В случае единственного кластера потребуется лишь одна копия всех ресурсов, необходимых для запуска кластера Kubernetes и управления им.
Например, это справедливо для мастер-узлов. Обычно на каждый кластер Kubernetes приходится по 3 мастер-узла, поэтому для одного единственного кластера их число таким и останется (для сравнения, 10 кластерам понадобятся 30 мастер-узлов).
Вышеуказанная тонкость относится и другим сервисам, функционирующим в масштабах всего кластера, таким как балансировщики нагрузки, контроллеры Ingress, системы аутентификации, логирования и мониторинга.
В едином кластере все эти сервисы можно использовать сразу для всех рабочих нагрузок (не нужно создавать их копии, как в случае нескольких кластеров).
+ Дешевизна
Как следствие вышеизложенного, меньшее число кластеров обычно обходится дешевле, поскольку отсутствуют расходы на избыточные ресурсы.
Это особенно справедливо для мастер-узлов, которые могут стоить значительных денег независимо от способа размещения (on-premises или в облаке).
Некоторые управляемые (managed) сервисы Kubernetes, такие как Google Kubernetes Engine (GKE) или Azure Kubernetes Service (AKS), предоставляют управляющий слой бесплатно. В данном случае вопрос затрат стоит менее остро.
Также существуют managed-сервисы, взимающие фиксированную плату за работу каждого кластера Kubernetes (например, Amazon Elastic Kubernetes Service, EKS).
+ Эффективное администрирование
Управлять одним кластером проще, чем несколькими.
Администрирование может включать в себя следующие задачи:
В случае одного кластера заниматься всем этим придется только один раз.
Для множества кластеров операции придется повторять многократно, что, вероятно, потребует некой автоматизации процессов и инструментов, чтобы обеспечить систематичность и единообразие процесса.
А теперь несколько слов о минусах.
− Единая точка отказа
В случае отказа единственного кластера перестанут работать сразу все рабочие нагрузки!
Существует масса вариантов, когда что-то может пойти не так:
− Отсутствие жесткой изоляции
Работа в общем кластере означает, что приложения совместно используют аппаратное обеспечение, сетевые возможности и операционную систему на узлах кластера.
В определенном смысле два контейнера с двумя различными приложениями, работающие на одном и том же узле, подобны двум процессам, работающим на одной и той же машине под управлением одного и того же ядра ОС.
Контейнеры Linux обеспечивают некоторую форму изоляции, но она далеко не так сильна, как та, которую обеспечивают, скажем, виртуальные машины. В сущности, процесс в контейнере — это тот же процесс, запущенный в операционной системе хоста.
Это может стать проблемой с точки зрения безопасности: подобная организация теоретически позволяет несвязанным приложениям взаимодействовать друг с другом (намеренно или случайно).
Кроме того, все рабочие нагрузки в кластере Kubernetes совместно используют некоторые общекластерные сервисы, такие как DNS — это позволяет приложениям находить Service’ы других приложений в кластере.
Все вышеперечисленные пункты могут иметь разное значение в зависимости от требований, предъявляемых к безопасности приложений.
Kubernetes предоставляет различные инструменты для предотвращения проблем в системе безопасности, такие как PodSecurityPolicies и NetworkPolicies. Однако для их правильной настройки требуется определенный опыт кроме того, они не в состоянии закрыть абсолютно все дыры в безопасности.
Важно всегда помнить, что Kubernetes изначально разработан для совместного использования, а не для изоляции и безопасности.
− Отсутствие жесткой multi-tenancy
Учитывая обилие общих ресурсов в кластере Kubernetes, существует множество способов, которыми различные приложения могут «наступать друг другу на пятки».
Например, приложение может монополизировать некий общий ресурс (вроде процессора или памяти) и лишить другие приложения, работающие на том же узле, доступа к нему.
Kubernetes обеспечивает различные механизмы контроля за подобным поведением, такие как запросы ресурсов и лимиты (см. также статью « CPU-лимиты и агрессивный троттлинг в Kubernetes » — прим. перев.), ResourceQuotas и LimitRanges. Однако, как и в случае безопасности, их настройка достаточно нетривиальна и они не способны предотвратить абсолютно все непредвиденные побочные эффекты.
− Большое число пользователей
В случае единственного кластера приходится открывать доступ к нему множеству людей. И чем значительнее их число, тем выше риск того, что они что-нибудь «сломают».
Внутри кластера можно контролировать, кто и что может делать с помощью управления доступом на основе ролей (RBAC) (см. статью « Пользователи и авторизация RBAC в Kubernetes » — прим. перев.). Впрочем, оно не помешает пользователям «сломать» что-то в границах своей зоны ответственности.
− Кластеры не могут расти до бесконечности
Кластер, который используется для всех рабочих нагрузок, будет, вероятно, весьма большим (по числу узлов и pod’ов).
Но тут возникает другая проблема: кластеры в Kubernetes не могут расти до бесконечности.
Существует теоретический предел на размер кластера. В Kubernetes он составляет примерно 5000 узлов, 150 тыс. pod’ов и 300 тыс. контейнеров.
Однако в реальной жизни проблемы могут начаться гораздо раньше — например, всего при 500 узлах.
Дело в том, что крупные кластеры оказывают высокую нагрузку на управляющий слой Kubernetes. Другими словами, чтобы поддерживать кластер в рабочем состоянии и эффективно использовать ресурсы, требуется тщательная настройка.
Эта проблема изучается в соответствующей статье в оригинальном блоге под названием «Architecting Kubernetes clusters — choosing a worker node size».
Но давайте рассмотрим противоположный подход: множество мелких кластеров.
2. Множество небольших, специализированных кластеров
При данном подходе вы используете отдельный кластер для каждого развертываемого элемента:
Множество мелких кластеров
Для целей этой статьи под развертываемым элементом понимается экземпляр приложения — например, dev-версия отдельного приложения.
В данной стратегии Kubernetes используется как специализированная среда выполнения для отдельных экземпляров приложения.
Давайте рассмотрим плюсы и минусы этого подхода.
+ Ограниченный «радиус взрыва»
При «поломке» кластера негативные последствия ограничиваются лишь теми рабочими нагрузками, которые были развернуты в этом кластере. Все другие workload’ы остаются нетронутыми.
+ Изоляция
Рабочие нагрузки, размещенные в индивидуальных кластерах, не имеют общих ресурсов, таких как процессор, память, операционная система, сеть или другие сервисы.
В результате мы получаем жесткую изоляцию между несвязанными приложениями, что может благоприятно сказаться на их безопасности.
+ Малое число пользователей
Учитывая, что в каждом кластере содержится лишь ограниченный набор рабочих нагрузок, сокращается число пользователей с доступом к нему.
Чем меньше людей имеют доступ к кластеру, тем ниже риск того, что что-то «сломается».
Давайте посмотрим на минусы.
− Неэффективное использование ресурсов
Как упоминалось ранее, каждому кластеру Kubernetes требуется определенный набор управляющих ресурсов: мастер-узлы, компоненты контрольного слоя, решения для мониторинга и ведения логов.
В случае большого числа малых кластеров приходится выделять бóльшую долю ресурсов на управление.
− Дороговизна
Неэффективное использование ресурсов автоматически влечет за собой высокие затраты.
Например, содержание 30 мастер-узлов вместо трех при той же вычислительной мощности обязательно отразится на расходах.
− Сложности администрирования
Администрировать множество кластеров Kubernetes гораздо сложнее, чем работать с одним.
Например, придется настраивать аутентификацию и авторизацию для каждого кластера. Обновление версии Kubernetes также придется проводить по несколько раз.
Скорее всего, придется применить автоматизацию, чтобы повысить эффективность всех этих задач.
Теперь рассмотрим менее экстремальные сценарии.
3. Один кластер на каждое приложение
В рамках этого подхода вы создаете отдельный кластер для всех экземпляров конкретного приложения:
Кластер на приложение
Такой путь можно рассматривать как обобщение принципа «отдельный кластер на команду», поскольку обычно команда инженеров занимается разработкой одного или нескольких приложений.
Давайте рассмотрим плюсы и минусы этого подхода.
+ Кластер можно подстроить под приложение
Если у приложения имеются особые потребности, их можно реализовать в кластере, не затрагивая другие кластеры.
Такие потребности могут включать worker’ы с GPU, определенные плагины CNI, service mesh или какой-нибудь другой сервис.
Каждый кластер можно подстроить под работающее в нем приложение, чтобы он содержал только то, что необходимо.
− Разные среды в одном кластере
Недостатком этого подхода является то, что экземпляры приложений из разных окружений сосуществуют в одном кластере.
Например, prod-версия приложения работает в том же кластере, что и dev-версия. Это также означает, что разработчики ведут свою деятельность в том же кластере, в котором эксплуатируется production-версия приложения.
Если из-за действий разработчиков или глюков dev-версии в кластере произойдет сбой, то потенциально может пострадать и prod-версия — огромный недостаток такого подхода.
Ну и, наконец, последний сценарий в нашем списке.
4. Один кластер на каждое окружение
Данный сценарий предусматривает выделение отдельного кластера на каждое окружение:
Один кластер на окружение
К примеру, у вас могут быть кластеры dev, test и prod, в которых вы будете запускать все экземпляры приложения, предназначенные для определенной среды.
Вот плюсы и минусы такого подхода.
+ Изоляция prod-среды
В рамках этого подхода все окружения оказываются изолированными друг от друга. Однако на практике это особенно важно для prod-среды.
Production-версии приложения теперь не зависят от происходящего в других кластерах и средах.
Таким образом, если в dev-кластере внезапно возникнет проблема, prod-версии приложений продолжат работать как будто ничего не случилось.
+ Кластер можно подстроить под среду
Каждый кластер можно подстроить под его окружение. Например, можно:
+ Ограничение доступа к production-кластеру
Необходимость работать с prod-кластером напрямую возникает нечасто, так что можно значительно ограничить круг лиц, имеющих к нему доступ.
Можно пойти еще дальше и вообще лишить людей доступа к этому кластеру, а все развертывания выполнять с помощью автоматизированного инструмента CI/CD. Подобный подход позволит максимально снизить риск человеческих ошибок именно там, где это наиболее актуально.
А теперь несколько слов о минусах.
− Отсутствие изоляции между приложениями
Основной недостаток подхода — отсутствие аппаратной и ресурсной изоляции между приложениями.
Несвязанные приложения совместно используют ресурсы кластера: системное ядро, процессор, память и некоторые другие службы.
Как уже упоминалось, это может быть потенциально опасным.
− Невозможность локализовать зависимости приложений
Если у приложения имеются особые требования, то их приходится удовлетворять во всех кластерах.
Например, если приложению необходим GPU, то каждый кластер должен содержать по крайней мере один worker с GPU (даже если он используется только этим приложением).
В результате мы рискуем получить более высокие издержки и неэффективное использование ресурсов.
Заключение
При наличии определенного набора приложений их можно разместить в нескольких больших кластерах или во множестве малых.
В статье рассмотрены плюсы и минусы различных подходов, начиная от одного глобального кластера и заканчивая несколькими небольшими и узкоспециализированными:
Как обычно, ответ зависит от сценария использования: необходимо взвесить плюсы и минусы разных подходов и выбрать наиболее оптимальный вариант.
Однако выбор не ограничивается приведенными выше примерами — можно задействовать любое их сочетание!
Например, можно организовать по паре кластеров на каждую команду: кластер для разработки (в котором будут окружения dev и test) и кластер для production (где будет находиться production-среда).
Опираясь на информацию из этой статьи, вы сможете соответствующим образом оптимизировать плюсы и минусы под конкретный сценарий. Удачи!
Поднимаем кластер для обслуживания веб-приложений без записи состояния (stateless web applications) вместе с ingress, letsencrypt, не используя средства автоматизации вроде kubespray, kubeadm и любых других.
Время на чтение:
45-60 минут, на воспроизведение действий: от 3-х часов.
Преамбула
На написание статьи меня сподвигла потребность в своём собственном кластере kubernetes для экспериментов. Автоматические решения установки и настройки, которые есть в открытом доступе, не работали в моем случае, так как я использовал не-мейнстримовые дистрибутивы Linux. Плотная работа с kubernetes в IPONWEB стимулирует иметь такую площадку, решая свои задачи в комфортном ключе, в том числе и для домашних проектов.
Компоненты
В статье будут фигурировать следующие компоненты:
— Ваш любимый Linux — я использовал Gentoo (node-1: systemd / node-2: openrc), Ubuntu 18.04.1.
— Kubernetes Server — kube-apiserver, kube-controller-manager, kube-scheduler, kubelet, kube-proxy.
— Containerd + CNI Plugins (0.7.4) — для организации контейнеризации возьмем containerd + CNI вместо docker (хотя изначально вся конфигурация была поднята на docker, так что ничего не помешает использовать его в случае необходимости).
— CoreDNS — для организации service discovery компонентов, работающих внутри kubernetes кластера. Рекомендована версия не ниже 1.2.5, так как с этой версии появляется вменяемая поддержка работы coredns в качестве процесса, запущенного вне кластера.
— Flannel — для организации сетевого стека, общения подов и контейнеров между собой.
— Ваша любимая db.

Ограничения и допущения
Введение
В ходе работы я пользовался большим количеством источников, но хочу отметить отдельно достаточно подробное руководство Kubernetes the hard way, которое освещает около 90% вопросов базовой конфигурации собственного кластера. Если вы уже ознакомились с этим руководством, можете смело переходить сразу к части Конфигурация Flannel
Список терминов / Глоссарий
Сетевая архитектура решения
После того как первая версия кластера заработала, я решил перестроить его так, чтобы разграничить узлы, ответственные за запуск приложений внутри кластера (рабочие узлы, они же workers), и API мастер-сервера.
В результате я получил ответ на вопрос: «Как получить более-менее недорогой, но функционирующий кластер, если я хочу размещать там не самые толстые приложения».
(Планируется быть таким)
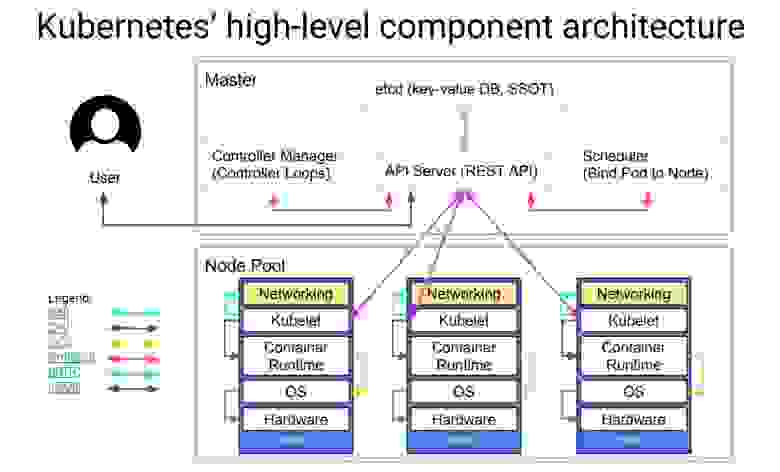
(Скрадено из интернетов, если кто-то вдруг еще не знает или не видел)
Компоненты и их производительность
Можно было найти VPS/VDS дешевле при размещении серверов на территории России или СНГ, но печальные истории, связанные с РКН и его действиями, создают определенные риски и порождают естественное желание их избежать.
Нет, не нужен. Мастер-узлу не требуется docker или containerd как таковой, хотя в интернете есть большое количество руководств, которые для тех или иных нужд включают использование окружения для контейнеризации. В рассматриваемой конфигурации выключение containerd из списка зависимостей было сделано преднамеренно, однако, каких-то очевидных плюсов такого подхода я не выделяю.
Конфигурация, предоставленная выше, является минимальной и достаточной для того, чтобы запустить кластер. Никаких дополнительных действий/компонент не требуется, разве что вы захотите что-то добавить по своему усмотрению.
Для построения тестового кластера или кластера для домашних проектов будет вполне достаточно 1vCPU/1G RAM для функционирования мастер-нода. Разумеется, нагрузка на мастер-ноду будет изменяться в зависимости от количества задействованных рабочих узлов (workers), а также наличия и объема сторонних запросов к api-server.
Я разнес master и worker конфигурации следующим образом:
Конфигурация
Для конфигурации мастера необходимо функционирование следующих компонентов:
etcd — для хранения данных для api-server’а, а также для flannel;
kube-apiserver — собственно, api-server;
kube-controller-manager — для генерации и обработки событий;
kube-scheduler — для распределения зарегистрированных через api-server ресурсов — например, подов.
Для конфигурации «рабочих лошадок» необходимо функционирование следующих компонентов:
kubelet — для запуска подов, обеспечения конфигурирования сетевых настроек;
kube-proxy — для организации маршрутизации/балансировки kubernetes сервисов;
coredns — для service discovery внутри запущенных контейнеров;
flannel — для организации сетевого доступа контейнеров, работающих на разных узлах, а также для динамического распределения сетей по узлам (kubernetes node) кластера.
Тут следует сделать маленькое отступление: coredns может быть запущен и на мастер-сервере. Ограничений, которые бы заставили запускать coredns именно на рабочих узлах, нет, кроме нюанса конфигурации coredns.service, который попросту не запустится на стандартном/немодифицированном Ubuntu сервере из-за конфликта с сервисом systemd-resolved. Я и не стремился решить эту проблему, так как меня вполне устраивали 2 ns сервера, расположенные на рабочих узлах.
Чтобы сейчас не тратить времени на ознакомление со всеми деталями процесса конфигурирования компонентов, предлагаю самостоятельно ознакомиться с ними в руководстве Kubernetes the hard way. Я же сосредоточусь на отличительных особенностях моего варианта конфигурирования.
Файлы
Все файлы для функционирования компонентов кластера для мастера и рабочих узлов помещены в /var/lib/kubernetes/ для удобства. При необходимости вы можете разместить их иным образом.
Сертификаты
Основой для генерации сертификатов служит все тот же Kubernetes the hard way, существенных отличий практически нет. Для перегенерации подчиненных сертификатов были написаны простые bash скрипты вокруг cfssl приложений — это очень пригодилось в процессе отладки.
Вы можете сгенерировать сертификаты под ваши нужды, пользуясь предложенными ниже скриптами, рецептами из Kubernetes the hard way или другими подходящими инструментами.
Взять скрипты можно тут: kubernetes bootstrap. Перед запуском отредактируйте файл certs/env.sh, указав ваши настройки. Пример:
Если вы воспользовались env.sh и корректно указали все параметры, то необходимости трогать сгенерированные сертификаты нет. Если вы ошиблись на каком-то этапе, то сертификаты можно перегенерировать по частям. Приведенные bash скрипты тривиальны, разобраться в них не составит сложности.
Важное замечание — не стоит часто пересоздавать ca.pem и ca-key.pem сертификаты, так как они являются корневыми для всех последующих, иными словами, вам придется пересоздать все сопутствующие сертификаты и доставить их на все машины и во все нужные директории.
Мастер
Нужные сертификаты для запуска сервисов на мастер-узле следует положить в /var/lib/kubernetes/ :
kubernetes.pem — необходим для flannel, coredns при подключении к etcd, kube-apiserver.
Данная особенность выполнена по логике конфигурации Kubernetes the hard way.
Исходя из этого, данный файл нужен будет везде — и на мастере, и на рабочих узлах. Я не стал менять подход, предоставленный оригинальным руководством, так как с его помощью можно быстрее и нагляднее организовать работу кластера и понять весь ворох зависимостей.
Моё личное мнение состоит в том, что для etcd нужны отдельные сертификаты, никак не пересекающиеся с сертификатами, использующимися для работы kubernetes.
Рабочие узлы
Отладка сертификатов
Все остальные сертификаты для kubelet и kube-proxy вшиты непосредственно в соответствующие kubeconfig’и.
kubeconfig
Все нужные kubeconfig’и можно сделать с помощью Kubernetes the hard way, однако, здесь и начинаются некоторые отличия. Руководство использует kubedns и cni bridge конфигурацию, здесь же рассматривается coredns и flannel. Эти два сервиса, в свою очередь, используют kubeconfig для авторизации в кластере.
Мастер
Для мастера необходимы следующие kubeconfig файлы (как упомянуто выше, после генерации их можно взять в certs/kubeconfig ):
Данные файлы потребуются для запуска каждого из компонентов-сервисов.
Рабочие узлы
Для рабочих узлов необходимы следующие kubeconfig файлы:
Запуск сервисов
Несмотря на то, что на моих рабочих узлах используются разные системы инициализации, в примерах и в репозитории даны варианты с использованием systemd. С их помощью проще всего понять, какой процесс и с какими параметрами необходимо запустить, кроме того, они не должны вызвать больших проблем при изучении сервисов с флагами назначений.
Для запуска сервисов необходимо скопировать service-name.service в /lib/systemd/system/ или любой другой каталог, где размещаются сервисы для systemd, и после этого включить и запустить сервис. Пример для kube-apiserver:
Не торопитесь запускать все серверы сразу, для начала достаточно будет включить etcd и kube-apiserver. Если все прошло удачно, и у вас сразу заработали все четыре сервиса на мастере, запуск мастера можно считать успешным.
Мастер
Можно воспользоваться systemd настройками или сгенерировать init скрипты для конфигурации, которую вы используете. Как уже было сказано, для мастера вам необходим:
Рабочие узлы
Клиент
Скачайте kubectl и проверьте работу kube-apiserver. Еще раз напомню, что на данном этапе для работы kube-apiserver должен функционировать только etcd. Остальные компоненты понадобятся для полноценной работы кластера несколько позже.
Проверяем, что kube-apiserver и kubectl работают:
Конфигурация Flannel
В качестве конфигурации flannel я остановился на vxlan бэкенде. Подробнее о бэкендах можно почитать тут.
Сразу скажу, что запуск kubernetes кластера на VPS скорее всего ограничит вас в использовании host-gw бэкенда. Не являясь опытным сетевым инженером, я потратил примерно два дня на отладку, чтобы понять, в чем крылась проблема с его использованием на популярных VDS/VPS провайдерах.
Были протестированы linode.com и digitalocean. Суть проблемы заключается в том, что провайдеры не предоставляют честную L2 для частной сети (private networking). Это, в свою очередь, делает невозможным хождение сетевого трафика между узлами в такой конфигурации:
Для того чтобы работал сетевой трафик для подов между нодами, хватит обычной маршрутизации. Не забудьте, что net.ipv4.ip_forward должен быть установлен в 1, а FORWARD цепочка в filter таблице не должна содержать для узлов запрещающих правил.
Именно это и не работает на указаных (а, скорее всего, и вообще на всех) VPS/VDS.
Для установки нужной конфигурации flannel можно воспользоваться set-flannel-config.sh из etc/flannel. Важно помнить: если вы решите поменять backend, необходимо будет удалить конфигурацию в etcd и перезапустить все flannel демоны на всех узлах, — поэтому выбирайте его с умом. По умолчанию используется vxlan.
После того как вы прописали нужную конфигурацию в etcd, необходимо настроить сервис для его запуска на каждом из рабочих узлов.
flannel.service
Пример для сервиса можно взять тут: systemd/flannel
Настройка
Как было описано ранее, нам необходимы ca.pem, kubernetes.pem и kubernetes-key.pem файлы для авторизации в etcd. Все остальные параметры не несут в себе какого-то сакрального смысла. Единственное, что действительно важно — это сконфигурировать глобальный ip адрес, через который будут ходить сетевые пакеты между сетями:
(Multi-Host Networking Overlay with Flannel)
После успешного запуска flannel вы должны обнаружить сетевой интерфейс flannel.N в своей системе:
Проверить, что ваши интерфейсы работают корректно на всех узлах, достаточно просто. В моем случае node-1 и node-2 имеют 10.200.8.0/24 и 10.200.12.0/24 сети соответственно, поэтому обычным icmp запросом проверяем их доступность:
В случае возникновения каких-либо проблем рекомендуется проверить, нет ли каких-либо режущих правил в iptables по UDP между хостами.
Конфигурация Containerd
Разместите etc/containerd/config.toml в /etc/containerd/config.toml или где вам удобно, главное — не забудьте поменять путь к файлу конфигурации в сервисе (containerd.service, описан ниже).
containerd.service
Настройка
После того, как у вас что-то появится внутри вашего kubernetes кластера, crictl станет более полезным и начнет отображать поды, контейнеры, образы и так далее.
Конфигурация CNI Plugins
Про CNI уже писали на Хабре, поэтому просто сошлюсь на подходящую статью по теме и, не вдаваясь в подробности, перейду к делу.
Настройка
Для каждого из рабочих узлов скачиваем cni plugins для нужной нам платформы и распаковываем в /opt/cni/bin/
в /etc/cni/net.d кладем следующие файлы с указанным содержанием:
Описания проверки этого сетапа перегрузит эту статью, поэтому его я пропущу. Но тем, кто привык рисковать и не боится сложностей, советую к прочтению Red Hat заменяет Docker на Podman, Intro to Podman
Конфигурация Kubelet
Перед тем, как скопировать etc/kubelet-config.yaml в нужное место, необходимо отредактировать его в соответствии с вашими настройками, как и все конфигурационные файлы. Ниже я отмечу данные опции:
К сожалению, о них можно прочитать только в декларация GO файлов kubernetes, поэтому гуглите, исходя из собственного опыта и желания разобраться. Конкретно эти опции отвечают за резервирование системных ресурсов. При такой конфигурации из ресурсов вашего реального кластера будет зарезервировано 0.2 vCPU и 600 MB памяти для использования хостовой системой.
Это могут быть, к примеру, kubelet, kube-proxy, coredns, flannel или другие системные процессы. Разумеется, данные настройки не являются универсальными и указаны в соответствии с конфигурацией моих рабочих узлов — в моём случае это 2 vCPU / 4G ram, плюс на обоих узлах у меня все еще крутятся старые проекты, которые не переведены в kubernetes + postgresql сервера.
В случае использования микро-узлов (micro nodes) я бы вообще удалил данную часть конфигурационного файла.
kubelet.service
Пример service файла можно взять тут: systemd/kubelet
Настройка
Я не уделял особенного внимания сущностям, которые обслуживают RBAC, поэтому в текущей конфигурации требуется выделение прав для корректного функционирования каждого из узлов под управлением kubelet.
Примените etc/kubelet-default-rbac.yaml для того, чтобы kubelet имел необходимые права для манипулирования ресурсами на узле:
После того, как ресурсы были созданы, можно приступить к конфигурации и запуску самого сервиса.
Если все прошло успешно, то вы должны как минимум увидеть узел через запрос узлов api сервера:
Конфигурация Kube Proxy
Сервис: systemd/kubelet. Тут все просто, особой магии нет, kube-proxy-config.yaml можно взять опять же тут: etc/kube-proxy
kube-proxy.service
Настройка
Так как kube-proxy отвечает за «проделываение» маршрутов внутири iptables, то проверить его работу можно будет только после того, как вы что-то запустите внутри kubernetes кластера (какой-нибудь сервис). Об этом ниже.
Конфигурация CoreDNS
Corefile можно взять тут: etc/coredns/Corefile, выглядит он следующим образом:
Вам необходимо будет скопировать coredns.kubeconfig и pem-сертификаты (процесс их генерации описан выше) на все worker узлы. Вдобавок, coredns сервис я запускал без работающего systemd-resolved. Поэтому, если вы захотите запустить данный конфиг на стоковом Ubuntu сервере, то он, скорее всего, не заработает, как нужно. Но исправить его не так уж и сложно.
coredns.service
Настройка
Проверить, что все ок, можно следующим образом:
Как мы видим, coredns вернул нам ip адрес стандартного kubernetes сервиса.
Важно, kubernetes.default сервис будет зарегистрирован работающим kube-controller-manager, поэтому стоит убедиться в его наличии:
nginx-ingress & cert-manager
Чтобы запустить приложение, необходимо определить его ресурсы. А перед этим следует сконфигурировать и установить nginx-ingress и cert-manager.
После того, как все успешно запустилось, стоит проверить, работают ли процессы приложения:
Запускаем приложение
Чтобы протестировать конфигурацию, можно воспользоваться уже написанным приложением. Исходники лежат в том же репозитории, вместе с kubernetes resource конфигурацией: app/k8s
Следует обратить внимание, что генерация сертификата займет какое-то время. Также важно, чтобы доменное имя (в случае с данным примером это kubernetes-example.w40k.net), для которого вы генерируете сертификат, существовало и было доступно, иначе cert-manager в связке с nginx-ingress не смогут принять участвие в выпуске сертификата и вы не сможете использовать текущую конфигурацию. Тем не менее, вы можете использовать ingress без tls/ssl.
Данное приложение в указанной конфигурации создаёт:
На текущий момент это вся полезная информация, необходимая для первичной настройки функционирующих мастер- и рабочих узлов. Если у вас что-то не заработало или заработало не до конца, ниже представлена краткая сопроводительная информация, которая поможет в отладке и подгонке компонентов кластера.
Ссылки
Информация, которую я использовал для того, чтобы настроить кластер:
Полезно к прочтению:
, позже тут будут размещены ответы на самые популярные вопросы и замечания.
Отладочная информация
Данная секция к прочтению необязательна, особенно, если у вас все работает. Здесь собраны краткие инструкции, куда смотреть и как действовать в ситуации, если что-то не работает, или работает не так, как ожидается.
Api Server
Если данный запрос (замените токен на свой) возвращает HTTP 200 OK + содержимое, то api-server функционирует корректно:
Kube Controller Manager
После того, как controller manager соединится с api сервером и начнет работать, он произведет некоторый набор стандартных действий. Для проверки результата достаточно будет убедиться в том, что были созданы service account’ы:
Если этот список пуст, убедитесь в том, что kube-controller-manager функционирует корректно.
Kube Scheduler
Как мы видим, default-scheduler успешно распределил pod на узел w40k.net. Если с планировщиком что-то не так, то об этом можно будет узнать из обработанных или необработанных событий — и принять необходимые меры.
При настройке и конфигурациях у меня не возникло большого количества проблем непосредственно с планировщиком. Вот, пожалуй, единственная обнаруженная странность, — планировщик время от времени самопроизвольно «останавливался». Эта проблема разрешилась переходом сервиса на systemd с его встроенными возможностями по перезапуску падающих сервисов.
Подробнее про kube scheduler читайте тут или перевод тут
Kubelet
Чуть подробнее можно узнать тут (и перевод тут)
Kube Proxy и Сервисы
Само по себе функционирование kube-proxy зависит от двух факторов:
Важно, 10.32.0.0/24 адреса явлаются «виртуальными». То есть, их не прослушивает ни один из сетевых интерфейсов. По сути это правила iptables, то есть правила маршрутизации трафика, которые будут применены, как только вы попытаетесь что-то запросить по данному адресу+порту. Вы не можете послать icmp запросы на эти адреса, поэтому стандартный способ проверить сервис ping’ом не сработает. Отсутствие результата не будет свидетельствовать ни о поломке, ни о корректном его функционировании.
Для того, чтобы проверить корректную работу kube-proxy, можно отправить запрос на созданный сервис с любого узла и посмотреть на результат его работы:
Нас будет интересовать вторая пара src/dst (9 и 10 столбцы). Как мы видим, тут src меняется и имеет два уникальных значения:
Это означает, что сервис работает корректно. Если вы видите только один адрес, то какой-то контейнер (скорее всего, расположенный на другом узле) не функционирует. Для отладки этой проблемы можно воспользоваться тестированием непосредственно сети.
Если вдруг вы обнаружили, что оба адреса функционируют, но в таблице conntrack у вас все равно указан только один адрес, это означает, что проблема находится на уровне kube-proxy. Проверьте функционирование сервиса, а также содержимое ваших маршрутов в nat таблице:
Также стоит проделать эту операцию на всех узлах вашего кластера.
Во время финальной подгонки я столкнулся с проблемой постоянной задержки при отправке запроса через сервис на другой узел. К сожалению, я не смог найти, с чем это может быть связано. Как ни странно, проявилось это только на одном из узлов. Если кто-то знает возможные причины и решение этой проблемы, пожалуйста, напишите в комментариях.
Интересную информацию можно почерпнуть тут и перевод тут



