Загрузить навигационные точки POI в ваш Nissan

Объекты POI или точки интереса (от англ. points of interest) — это объекты инфраструктуры, достопримечательности, природные объекты и важные точки на дорогах, координаты и информация о которых нанесены на GPS карту.
К точкам POI относятся: гостиницы, рестораны, АЗС, больницы, магазины, кинотеатры, музеи, банкоматы, аптеки и множество других объектов. Также к точкам POI относятся стенции метро, вокзалы, аэропорты и прочие транспортные узлы. Отдельно выделяются дорожные POI: это посты ДПС, «лежачие полицейские», камеры, радары, железнодорожные переезды и прочие зоны повышенного внимания. Точки POI могут сопровождаться аудио предупреждениями.
Как загрузить точки в Ваш Nissan Connect:
1. Вам понадобится Flash-карта, лучше всего отформатированная в формате FAT. На карте необходимо будет создать папки со следующей последовательностью
X:\myPOIs\myPOIWarnings\speedcam.csv, где X — имя диска флэшки.
2. Необходимо загрузить свежие точки POI с ресурса mapcam.info/speedcam/, где вы должны зарегистрироваться, что бы получить доступ к загрузке.
Снимок
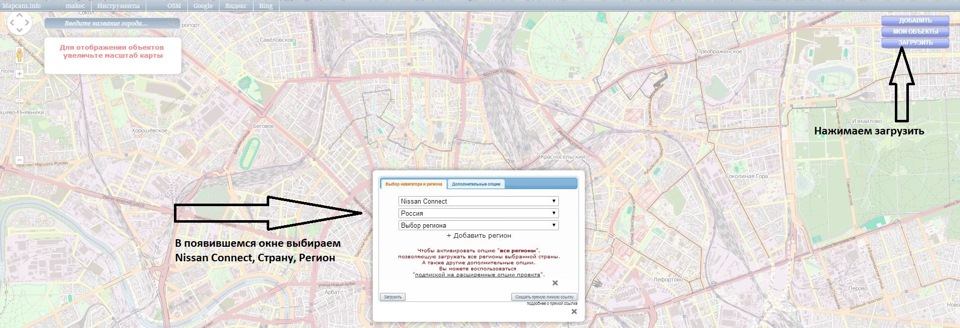
Выбираем необходимые нам данные
(Во вкладке «дополнительные опции» можно выбрать тот тип POI, которые Вам нужны)
Снимок2
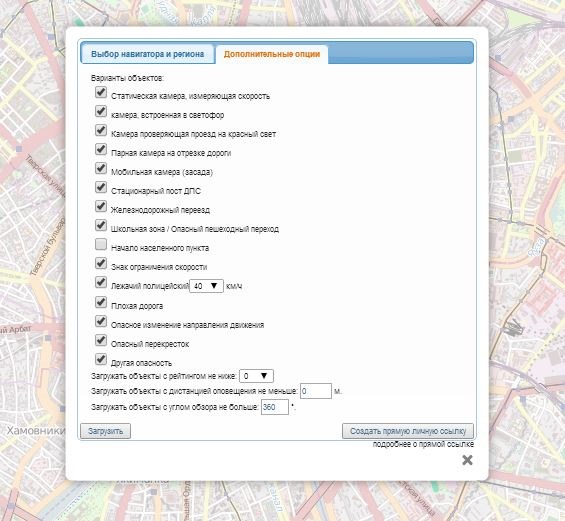
Файл не должен превышать более 2мб в размере, иначе Nissan Connect не сможет их загрузить!
Как мы персонализировали POI
Мы в 2ГИС хотим облегчить пользовательскую поисковую рутину и потому стремимся предугадывать запросы пользователей. Под катом расскажем про то, как мы придумали алгоритм для персонализации интересных мест и что из этого вышло.

POI (point of interest) — маленькая круглая иконка на карте. Обозначает место или компанию, которые могут представлять интерес для пользователя.
Вот они — POI 2ГИС. У каждой рубрики своя иконка
Объекты POI — популярные у большинства городские объекты в разных рубриках. А хочется учитывать ещё и интересы каждого пользователя отдельно. Поэтому мы решили добавить на карту персонализированные POI, которые будут отвечать за это.
Удачно подобранные POI ещё и сокращают цепочку шагов поиска на карте. Обычно пользователь ищет что-то так: открыл приложение → ввёл поисковый запрос → просмотрел выдачу → открыл карточку объекта.
С персонализированными POI пользователь может без поискового запроса сориентироваться на карте и найти информацию: открыл приложение → увидел нужный POI на карте → открыл карточку объекта.
Карта без персонализированных POI и с ними — интересными для пользователя рестораном, кофейней и клиникой
Данные
В качестве потенциальных объектов для POI логично брать те, к которым пользователь уже проявлял интерес. А среди них искать такие, к которым он вернётся с наибольшей вероятностью. При этом желательно, чтобы объекты интересовали пользователя как можно дольше — чтобы он привык искать их на карте.
Но как классифицировать эти данные? Можно разметить выборку объектов, обогатить множеством признаков и применить бустинг или нейронные сети. Но можно пойти другим путём — и придумать эмпирическое правило.
Эмпирическое правило
У эмпирического правила есть и плюсы, и минусы. Да, это даст более слабое качество классификации. Но главное преимущество — мы можем быстро и легко проверить востребованность POI. Подготовка данных, обучение такой модели и её внедрение займёт значительно меньше времени, чем, например, бустинг. А если фича окажется успешной как для пользователя, так и для компании, мы всегда сможем переключиться на более сложные и затратные модели.
Для эмпирических моделей важен хороший контекст в предметной области. Исследуя поведение пользователей в продукте, мы выяснили, что вероятность повторного обращения пользователя к продукту (retention rate) имеет экспоненциальное распределение.
Такое свойство есть не только у retention rate продукта, но и у многих других явлений, связанных с повторным обращением — например, повторное обращение к объекту, как в нашем случае. Это знание помогло нам разработать алгоритмы по определению «домашнего» города для пользователя, краткосрочных и долгосрочных пользовательских интересов.
Первый алгоритм
Первым делом сформировали выборку вида

 — n-мерный вектор признаков i-го объекта, а в качестве объекта классификации рассматриваем все объекты, которыми интересовался пользователь за определённое время до даты расчёта. В нашем случае это два месяца.
— n-мерный вектор признаков i-го объекта, а в качестве объекта классификации рассматриваем все объекты, которыми интересовался пользователь за определённое время до даты расчёта. В нашем случае это два месяца.
 — класс i-го объекта — отклик, который принимает значение, равное 1, если пользователь посетил фирмы в контрольный период времени, и 0, если не посетил.
— класс i-го объекта — отклик, который принимает значение, равное 1, если пользователь посетил фирмы в контрольный период времени, и 0, если не посетил.
Так как нам важны объекты, которые будут долго интересны пользователю, то в качестве контрольного периода выбрали месяц через две недели после даты расчёта. Этот лаг в две недели нужен, чтобы не захватить в число успешных объекты мгновенного/краткосрочного интереса — те, которые пользователь ищет прямо в дату расчёта или рядом с ней, но не факт, что вернётся к ним. Успешными считаем объекты с y=1 — то есть те, к которым пользователь вернулся во время контрольного периода.
Правило  , которое множеству признаков объекта Х ставит в соответствие его класс Y, выглядит так:
, которое множеству признаков объекта Х ставит в соответствие его класс Y, выглядит так:
где k — общее количество дней (или любой другой единицы времени) в обучающей выборке.
равно 1, если в день с номером i пользователь интересовался объектом, иначе 0. Номер дня равен 1 в первый день обучающей выборки и k в последний.
 — параметр, отвечающий за скорость изменения значимости дня взаимодействия с объектом по мере удаления от даты расчёта.
— параметр, отвечающий за скорость изменения значимости дня взаимодействия с объектом по мере удаления от даты расчёта.
 — пороговое значение.
— пороговое значение.
Идея в том, что чем дальше день, когда пользователь интересовался объектом, тем меньший вес будет у этого дня при оценке этого объекта. Параметры функции и подбираются путём максимизации целевой переменной:

где F — это F-мера с соответствующим соотношением желаемой точности и полноты модели. В этой задаче основной акцент на точности алгоритма, поэтому брали параметр  .
.

Результаты 1.0
Проверили алгоритм больше чем на 450 млн объектов. Среди них доля объектов с откликом, равным 1, составляет примерно 5%. Полнота алгоритма — 0.153, точность — 0.401, а F-мера  — 0.303.
— 0.303.
Качество такого алгоритма может показаться недопустимо низким. Дело в том, что в число объектов для классификации входят объекты, которые мы не можем отнести к долгосрочным интересам на основе данных метрик — пользователи интересовались ими слишком мало, чтобы делать какие-то выводы.
Только 3% объектов интересовали пользователя больше двух дней за обучающий период. В этом нет ничего удивительного: туда входят объекты из сфер с низким retention. Таких много, они могут быть очень крупными — например, аптеки, бары или просто объекты, которые не заинтересовали пользователя.
Среди объектов с откликом, равным 1, такой процент выше — 22%. Это тоже мало, но объясняется большим периодом между посещениями объекта.
Если исключить такие объекты, то при тех же параметрах модели полнота вырастает с 0.153 до 0.684 при той же точности в 0.401, а F-мера с акцентом на точности становится равной 0.437 — классическая, конечно, выше.
Однако при таком виде модели остаётся ещё две проблемы. Во-первых, у пользователей разный уровень активности: кто-то пользуется приложением раз в день, а кто-то — раз в месяц. Поэтому использование общего порогового значения и одних параметров весовой функции может занижать качество классификации.
Во-вторых, у объектов может быть разная частота посещения в зависимости от их сферы деятельности. Например, за продуктами в гипермаркет пользователь ездит стабильно раз в неделю, в парикмахерскую ходит раз в месяц, а при простуде может посещать поликлинику так часто, как скажет врач. Так что мы можем упускать объекты с большими интервалами посещения.
Второй алгоритм
Чтобы учесть эти проблемы, мы добавили в функцию признак, показывающий максимальный период пользовательского интереса, и немного иначе учли интенсивность посещения объекта и его актуальность. Разделили пользователей на три группы по частоте посещения продукта. Для каждой из них подобрали свои параметры этой модели:
k — количество дней в обучающей выборке.
 — номер последнего дня взаимодействия пользователя с объектом (равен 1 в первый день обучающей выборки и k в последний).
— номер последнего дня взаимодействия пользователя с объектом (равен 1 в первый день обучающей выборки и k в последний).
 — количество дней взаимодействия пользователя с объектом в рассматриваемом периоде.
— количество дней взаимодействия пользователя с объектом в рассматриваемом периоде.
 — количество дней между первым и последним днём взаимодействия пользователя с объектом в рассматриваемом периоде.
— количество дней между первым и последним днём взаимодействия пользователя с объектом в рассматриваемом периоде.
 — параметры функции, которые подбираются путём максимизации целевой переменной (в нашем случае это F-мера) аналогичным для первой модели образом.
— параметры функции, которые подбираются путём максимизации целевой переменной (в нашем случае это F-мера) аналогичным для первой модели образом.
Результаты 2.0
Оценили параметры и получили следующие результаты по кластерам пользователей.
| Кластер | Полнота | Точность | F-мера  |
|---|---|---|---|
| 1. Объекты пользователей, которые заходят в 2ГИС реже трёх раз в месяц | 0.072 | 0.349 | 0.197 |
| 2. Объекты пользователей, которые заходят в 2ГИС чаще трёх раз в месяц | 0.162 | 0.457 | 0.335 |
| 3. Объекты пользователей, которые заходят в 2ГИС чаще десяти раз в месяц | 0.194 | 0.514 | 0.386 |
| Итого по 2-му алгоритму | 0.177 | 0.492 | 0.363 |
| Итого по 1-му алгоритму | 0.153 | 0.401 | 0.303 |
F-мера увеличилась для всех кластеров, кроме первого — ему соответствует самая неактивная часть аудитории и на неё приходится не так много объектов.
Количество истинно-положительных объектов увеличилось на 17%. Прирост в точности составил 9.1%, а в полноте — 2.4%. Общая F-мера увеличилась на 6%.
Если исключить объекты с слишком маленьким количеством уникальных дней, то при тех же параметрах модели полнота вырастает с 0.177 до 0.802 (для первой модели 0.684, то есть прирост на 11.8%) при той же точности в 0.492 (для первой модели 0.401, то есть прирост на 9.1%). И если исходя из этого оценить F-меру , то для второго алгоритма она будет 0.533, а для первого 0.437, то есть прирост составляет 9.6%.
Итог эксперимента на бою
Декомпозиция данных и ввод дополнительных параметров значительно улучшили качество модели. Значит, более сложные модели могут повысить качество результата. Но прежде чем улучшать алгоритм, решили проверить фичу на бою и посмотреть, понравится ли она пользователям.
Персонализированные POI чуть больше обычных и появляются на карте раньше них
За месяц 500 000 пользователей сделали 1 млн кликов по персонализированным POI. Это примерно 12% от тех пользователей, кому мы их подобрали — но это не значит, что остальные пользователи не обратили на них внимание.
Примерно 40% от тех, кому подобрали персонализированные объекты, обращались к этим объектам другими способами. И это тоже хорошо — значит, есть потребность в персонализации не только на карте, но и в других составляющих продукта.
POI vs Избранное
Чтобы оценить, достаточно ли для нас таких результатов, мы решили сравнить персонализированные нами POI с объектами, которые пользователь персонализировал сам — с Избранным.
У персонализированных POI и Избранного похожая цель — запомнить места, в которые хочется вернуться. Похож и внешний вид — они отмечены иконками на карте и имеют примерно один и тот же масштаб отображения. Разница во внешнем виде: значок у всех объектов Избранного всегда один и тот же — белый флажок на оранжевом или красном фоне, а у персонализированных POI цвет и пиктограмма иконки меняется и зависит от отрасли объекта.
Персонализированные POI ещё и подскажут текстом, что за объект нас интересовал — в отличие от иконок Избранного без подписей
Оказалось, что доля пользователей с кликами в персональные POI больше, чем доля пользователей с кликами в Избранное с карты — в два раза среди тех, кому POI вообще были подобраны, и в полтора раза среди всех пользователей.
Фактически, мы сделали для пользователя обновляемое Избранное на карте, за которым ему не надо следить и вообще что-либо самому делать. Это довольно неплохой результат — поэтому есть смысл развивать персональные POI и дальше.
Выводы
Эмпирические модели могут быть полезны и эффективны на начальных этапах запуска фич и в условиях ограниченности ресурсов, потому что они могут дать результат быстро и дёшево. Главное — формировать предположения, исходя из глубокого понимания логики продукта, его природы и поведения пользователей.
Ну и ещё один вывод — будущее за персонализацией.
Как не переплачивать за рекламу в 2ГИС
И вот, у нас на календаре 25 число месяца. Звоните менеджеру(вы же взяли у него визиточку, верно?), говорите:»Знаете, у нас возникли некоторые трудности финансового характера, давайте отложим размещение на N месяцев». И тут из менеджера, как из рога изобилия польются акции, бонусы и прочие ништяки, такие как «мы вам логотип на карту подарим», «у нас скидка 20-30-40%, если вы со следующего месяца зайдете к нам в рекламное размещение».
2 ценовая категория имеет коэффициент 1.1, встречается почаще;
3 ценовая категория имеет коэффициент 1. Самая распространенная категория. ЭТу категорию имеют, наверное, 70% всех рубрик.
4 ценовая категория имеет коэффициент 0.75.
5 ценовая категория имеет коэффициент 0.5. Самая дешевая реклама именно в рубриках 5 ценовой категории.
Если компания имеет несколько рубрик, которые имеют разные ценовой категории, то расчет стоимости размещения будет производиться по самой дорогой рубрике. Пример: Компания «Рога и копыта» имеет рубрику 3 ценовой категории, две рубрики 5 ценовой категории. Стоимость базового пакета будет оценена по 3 ценовой категории. Понимаете, к чему я клоню?
Чтоб уменьшить стоимость размещения, просите менеджера подробный расчет стоимости размещения. Он покажет на экране ноутбука, с которым он пришел к вам на презентацию калькулятор «Продаван», в котором у каждой рубрики будет указан коэффициент стоимости. Просите удалить из расчета рубрики с коэффициентами 1-1.2, чтоб остались рубрики с коэффициентом 0.5 и вуаля! Стоимость размещения сократится на 40-50%.
Если рубрики 5 категории с коэффициентом 0.5 нет, просите менеджера подобрать такую рубрику. Это не займет много времени, все инструменты у него под рукой.
Этот способ подходит в том числе и для тех компаний, которые уже размещаются. В этом случае делается техническое расторжение. Никаких санкций не последует.
В заключении хочу сказать, что все эти способы можно комбинировать для максимальной экономии. Но! Не стоит злоупотреблять такой экономией, так как получите репутацию неблагонадежного клиента и ни один менеджер не захочет с Вами работать.
Изредка, менеджеры могут сами предложить сократить рекламный бюджет. В этом случае менеджер преследует свои интересы. Если он не сделал в этом месяце план и шансы сделать его призрачны, то ему проще в этом месяце сократить бюджет сейчас, чем в перегруженном месяце Вы решите прекратить рекламное размещение и ему придется перекрывать Вашу компанию другой компанией в своем портфеле. Либо, менеджер таким действием хочет заполучить вашу лояльность, чтоб позже сделать очень жирную допродажу.
Привет! Я Саша Гейдек, отвечаю за b2b-маркетинг в 2ГИС. Поясню несколько моментов из колонки, по порядку.
Условия рекламного размещения не зависят от юридической формы нашей работы в городе (франшиза или офис 2ГИС), а зависят от рынка: количества бизнесов, населения, спроса на товары и услуги и др. И понятно, что средний чек на «бизнес-ланч» в Москве и в Орле разный.
По поводу выгоды заключать рекламные контракты в конце месяца: условия зависят от конкретной позиции, и если бизнес заинтересован быть на первых строчках поисковой выдачи, лучше позаботиться о размещении заранее.
Про пожар у продажников в конце месяца — да. Не секрет, что компании планируют процессы и бюджеты в том числе помесячно, и мы не исключение. 2ГИС за самые успешные практики 🙂
По поводу возможности корректировки коэффициентов рубрик и стоимости рекламы. Реклама появится только в рубриках, где вы купите размещение. После удаления рубрики и восстановления ее, показы рекламы можно возобновить только со следующего месяца. То есть если реклама в определенной рубрике вам нужна, нет смысла ее убирать. И для рубрик цена разная. Если интерес фирмы в сфере стройматериалов, и рекламироваться она хочет там же, то реклама в этой рубрике будет дороже, чем в разделе «Новогодние товары» с выраженной сезонностью. Здесь тоже нет ноу-хау: чем больше претендентов на место, чем крупнее и востребованнее ниша, тем выше стоимость — аналог аукциона в контекстной рекламе в поисковиках.
И да, у нас есть система скидок. Например, скидка за период размещения и процент предоплаты. Компании, которые понимают, как работает геореклама, и видят эффект от вложений, готовы заключать с нами годовые контракты. Мы снижаем цену за счет объема. Так работают почти все поставщики наружной рекламы, индор, агентства и прочие.
По тезису о пиковых месяцах и последующем расторжении рекламного контракта — если запрос действительно сезонный, лучше на этапе формулирования задачи и УТП дать менеджеру знать, что ваш товар или услуга — сезонные. Наш специалист подберёт оптимальные рекламные опции на подходящий срок.
Если вы пока не готовы попробовать в рекламу в геосервисе, точно стоит зарегистрироваться в личном кабинете 2ГИС и проверить всю информацию о вашем бизнесе: обновить данные и добавить иллюстрации, которые привлекут клиентов. Здесь понятная инструкция, на что стоит обратить внимание.
2ГИС запускает API с данными о 1 000 000 организаций и возможностью заработать
2ГИС, как вы наверняка знаете, — это электронный справочник по 129 городам России и Украины. У нас более 8 млн пользователей и всегда актуальные данные. Сейчас в 2ГИС более 1 млн
POI.
Теперь любой разработчик сайта, мобильного или социального приложения может их использовать совершенно бесплатно через справочное API 2ГИС.
Что из себя представляют справочные данные 2ГИС?
 Это подробная информация по каждой организации в каждом городе — начиная от названия и контактов, заканчивая временем работы и способами оплаты услуг. Важно, что данные не просто собираются – их постоянно обновляют и дополняют сотни специалистов колл-центра 2ГИС по всей стране.
Это подробная информация по каждой организации в каждом городе — начиная от названия и контактов, заканчивая временем работы и способами оплаты услуг. Важно, что данные не просто собираются – их постоянно обновляют и дополняют сотни специалистов колл-центра 2ГИС по всей стране.
Другая особенность — уже с осени, в новой версии продукта, мы будем делиться с партнёрами
доходом от рекламы. Единицей рекламы является просмотр профиля рекламодателя, до 50%
стоимости которого получает партнёр. Здесь решается актуальная для многих площадок проблема
монетизации, ведь всем процессом, в том числе и поиском клиентов, занимается 2ГИС — а это
700 человек в отделах продаж 46 филиалов. Партнёру достаточно повышать популярность своего
проекта, получать деньги и тратить их на отдых на Мальте, например.
Наиболее очевидные способы использования API 2ГИС — это повышение качества и количества
контента для поисковых и справочных сервисов, городских порталов (E1.ru и Kazan24.ru уже
внедрили API 2ГИС), систем навигации, новые функциональные возможности для геосервисов,
тематических сайтов и приложений. Можно делать и совершенно новые приложения с
оригинальной идеей и нашими данными. В том числе под самые разные платформы. Так
уже сделала компания Wake Up Studios, например. Он выпустила 2ГИС для iPhone, опередив
официальную версию. Собственные проекты 2ГИС — онлайн-версия maps.2gis.ru и сайт отзывов
Flamp.ru — тоже работают на API.
Предвосхищая вопросы: API карт тоже появится в ближайшее время. И не только оно 😉
Все, что нужно для старта работы со справочным API 2ГИС — заполнить небольшую анкету на сайте
и получить ключ доступа. Там же есть документация, примеры и контактные данные, если у вас вдруг появятся вопросы.
PS На самом деле, этот пост должен был написать коллега kibik, так как именно он занимается API 2ГИС, но карма его подвела 🙂 Если поможете исправить ситуацию — я больше не буду постить чужие посты.
Что такое poi в 2гис

К точкам POI относятся: гостиницы, рестораны, АЗС, больницы, магазины, кинотеатры, музеи, банкоматы, аптеки и множество других объектов. Также к точкам POI относятся стенции метро, вокзалы, аэропорты и прочие транспортные узлы. Отдельно выделяются дорожные POI: это посты ДПС, «лежачие полицейские», камеры, радары, железнодорожные переезды и прочие зоны повышенного внимания. Точки POI могут сопровождаться аудио предупреждениями.
В программе АВТОСПУТНИК 5 набор объектов POI полностью интегрирован в карту. Расширение этого набора невозможно.
Для программы АВТОСПУТНИК 3 Вы можете скачать дополнительные наборы POI, который можно доустановить на навигатор.
Дополнительные объекты POI для АВТОСПУТНИК 3
Только для АВТОСПУТНИК 3
| Страна | Дорожные POI | Общие POI |
| Россия | Скачать | Скачать |
| Беларусь | Скачать | Скачать |
| Украина | Скачать | Скачать |
| Казахстан | Скачать |
Примечание
Как обновить точки POI
Только для АВТОСПУТНИК 3
Скачайте архив c дополнительными точками POI для нужной страны. Распакуйте файл, удалите из каталога \POI-waypoints\ старый файл для обновляемой страны (road_poi* для дорожных POI или poi* для общих) и замените его новым. Если старый файл не удалить, на карте появятся дубликаты точек POI.



