Введение в PostgreSQL
Что такое PostgreSQL. Установка сервера
PostgreSQL является одной из наиболее популярных систем управления базами данных. Сам проект postgresql эволюционировал из другого проекта, который назывался Ingres. Формально развитие postgresql началось еще в 1986 году. Тогда он назывался POSTGRES. А в 1996 году проект был переименован в PostgreSQL, что отражало больший акцент на SQL. И собственно 8 июля 1996 года состоялся первый релиз продукта.
С тех пор вышло множество версий postgresql. Текущей версией является версия 13. Однако регулярно также выходят подверсии.
PostgreSQL развивается как opensource. Исходный код проекта можно найти в репозитории на гитхабе по адресу https://github.com/postgres/postgres.
Установка
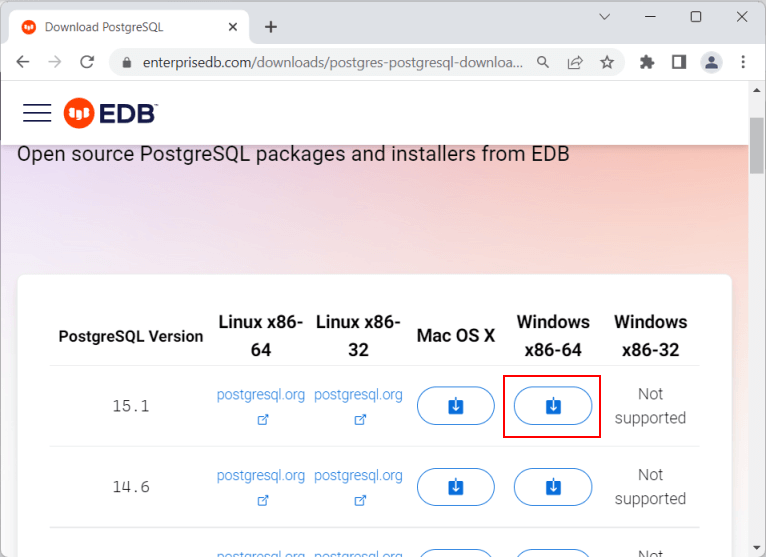
Тут же можно найти дитрибутивы и для других систем.
Запустим программу установки:
На следующем экране необходимо будет указать папку для установки. Оставим папку по умолчанию и перейдем к следующему шагу:
Далее будет предложено выбрать компоненты для установки:
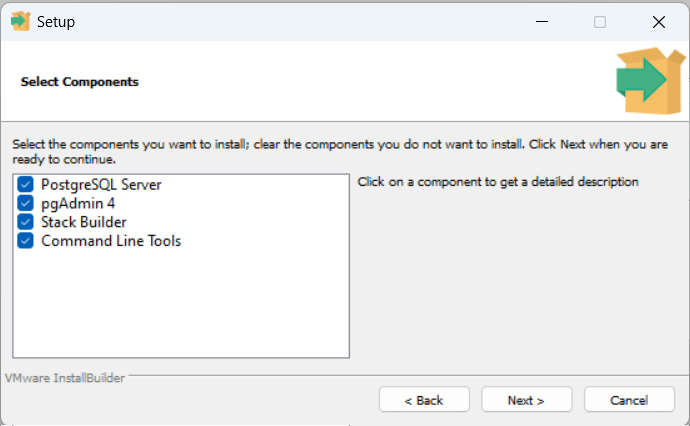
Оставим все компоненты по умолчанию и перейдем к следующему шагу. Далее будет предложено выбрать папку, где будут храниться базы данных:
Оставим путь по умолчанию и перейдем к следующему шагу. Затем необходимо будет установить пароль для суперпользователя postgres :
При установке запомним пароль, так как он потребуется для подключения к серверу. Затем нужно будет установить порт, по которому будет запускаться сервер. Можно оставить порт по умолчанию:
Далее можно будет установить локаль сервера. Оставим установку по умолчанию:
После этого мы увидим сводку по всем настройкам:
И если нас все устраивает, то можно нажать на кнопку Next, и начнется установка
И после завершения установки мы увидем следующее окно, и для выхода нажмем на кнопку Finish:
Таким образом, сервер PostgreSQL установлен, и мы можем начинать с ним работать.
PostgreSQL
Существует в реализациях для множества UNIX-like платформ, включая AIX, различные BSD-системы, HP-UX, IRIX, Linux, Mac OS X, Solaris/OpenSolaris, Tru64, QNX, а также для Microsoft Windows.
Содержание
Поддержка стандартов, возможности, особенности
На данный момент (версия 9.2.1), в PostgreSQL имеются следующие ограничения: [4]
| Максимальный размер базы данных | Нет ограничений |
| Максимальный размер таблицы | 32 Тбайт |
| Максимальный размер записи | 1,6 Тбайт |
| Максимальный размер поля | 1 Гбайт |
| Максимум записей в таблице | Ограничено размером таблицы |
| Максимум полей в таблице | 250—1600, в зависимости от типов полей |
| Максимум индексов в таблице | Нет ограничений |
Сильными сторонами PostgreSQL считаются:
Исторический очерк
PostgreSQL ведет свою «родословную» от некоммерческой СУБД Postgres, разработанной, как и многие open-source проекты, в Калифорнийском университете в Беркли. К разработке Postgres, начавшейся в 1986 году, имел непосредственное отношение Майкл Стоунбрейкер, руководитель более раннего проекта Ingres, на тот момент уже приобретённого компанией Computer Associates. Само название «Postgres» расшифровывалось как «Post Ingres», соответственно, при создании Postgres были применены многие уже ранее сделанные наработки.
Стоунбрейкер и его студенты разрабатывали новую СУБД в течение восьми лет, с 1986 по 1994 год. За этот период в синтаксис были введены процедуры, правила, пользовательские типы и многие другие компоненты. Работа не прошла даром — в 1995 году разработка снова разделилась: Стоунбрейкер использовал полученный опыт в создании коммерческой СУБД Illustra, продвигаемой его собственной одноимённой компанией (приобретённой впоследствии компанией Informix), а его студенты разработали новую версию Postgres — Postgres95, в которой язык запросов POSTQUEL — наследие Ingres — был заменен на SQL.
В этот момент разработка Postgres95 была выведена за пределы университета и передана команде энтузиастов. С этого момента СУБД получила имя, под которым она известна и развивается в текущий момент — PostgreSQL.
Основные возможности
Функции
Функции являются блоками кода, исполняемыми на сервере, а не на клиенте БД. Хотя они могут писаться на чистом SQL, реализация дополнительной логики, например, условных переходов и циклов, выходит за рамки собственно SQL и требует использования некоторых языковых расширений. Функции могут писаться с использованием одного из следующих языков:
PostgreSQL допускает использование функций, возвращающих набор записей, который далее можно использовать так же, как и результат выполнения обычного запроса.
Функции могут выполняться как с правами их создателя, так и с правами текущего пользователя.
Иногда функции отождествляются с хранимыми процедурами, однако между этими понятиями есть различие. С девятой версии возможно написание автономных блоков, которые позволяют выполнять код на процедурных языках без написания функций, непосредственно в клиенте.
Триггеры
Триггеры определяются как функции, инициируемые DML-операциями. Например, операция INSERT может запускать триггер, проверяющий добавленную запись на соответствия определённым условиям. При написании функций для триггеров могут использоваться различные языки программирования (см. выше).
Триггеры ассоциируются с таблицами. Множественные триггеры выполняются в алфавитном порядке.
Правила и представления
Механизм правил (англ. rules ) представляет собой механизм создания пользовательских обработчиков не только DML-операций, но и операции выборки. Основное отличие от механизма триггеров заключается в том, что правила срабатывают на этапе разбора запроса, до выбора оптимального плана выполнения и самого процесса выполнения. Правила позволяют переопределять поведение системы при выполнении SQL-операции к таблице. Хорошим примером является реализация механизма представлений (англ. views ): при создании представления создается правило, которое определяет, что вместо выполнения операции выборки к представлению система должна выполнять операцию выборки к базовой таблице/таблицам с учетом условий выборки, лежащих в основе определения представления. Для создания представлений, поддерживающих операции обновления, правила для операций вставки, изменения и удаления строк должны быть определены пользователем.
Индексы
В PostgreSQL имеется поддержка индексов следующих типов: B-дерево, хэш, R-дерево, GiST, GIN. При необходимости можно создавать новые типы индексов, хотя это далеко не тривиальный процесс. Индексы в PostgreSQL обладают следующими свойствами:
Многоверсионность (MVCC)
PostgreSQL поддерживает одновременную модификацию БД несколькими пользователями с помощью механизма Multiversion Concurrency Control (MVCC). Благодаря этому соблюдаются требования ACID, и практически отпадает нужда в блокировках чтения.
Типы данных
PostgreSQL поддерживает большой набор встроенных типов данных:
Более того, пользователь может самостоятельно создавать новые требуемые ему типы и программировать для них механизмы индексирования с помощью GiST.
Пользовательские объекты
PostgreSQL может быть расширен пользователем для собственных нужд практически в любом аспекте. Есть возможность добавлять собственные:
Наследование
Таблицы могут наследовать характеристики и наборы полей от других таблиц (родительских). При этом данные, добавленные в порождённую таблицу, автоматически будут участвовать (если это не указано отдельно) в запросах к родительской таблице.
Данная функциональность в текущее время не является полностью завершённой. Однако она достаточна для практического использования.
Прочие возможности
расширения для написания сложных выборок, отчётов и другую функциональность (API открыт).
Надёжность
Коммерческие расширения
История развития
Основные возможности СУБД по мере выхода новых версий
Курс молодого бойца PostgreSQL

Хочу поделиться полезными приемами работы с PostgreSQL (другие СУБД имеют схожий функционал, но могут иметь иной синтаксис).
Постараюсь охватить множество тем и приемов, которые помогут при работе с данными, стараясь не углубляться в подробное описание того или иного функционала. Я любил подобные статьи, когда обучался самостоятельно. Пришло время отдать должное бесплатному интернет самообразованию и написать собственную статью.
Данный материал будет полезен тем, кто полностью освоил базовые навыки SQL и желает учиться дальше. Советую выполнять и экспериментировать с примерами в pgAdmin‘e, я сделал все SQL-запросы выполнимыми без разворачивания каких-либо дампов.
1. Использование временных таблиц
При решении сложных задач трудно поместить решение в один запрос (хотя, многие стараются так сделать). В таких случаях удобно помещать какие-либо промежуточные данные во временную таблицу, для использования их в дальнейшем.
Такие таблицы создаются как обычные, но с ключевым словом TEMP, и автоматически удаляются после завершения сессии.
Ключ ON COMMIT DROP автоматически удаляет таблицу (и все связанные с ней объекты) при завершении транзакции.
2. Часто используемый сокращенный синтаксис Postgres
можно записать менее громоздко:
* (две тильды со звездочкой)
Поиск регулярными выражениями (имеет отличный от LIKE синтаксис)
оператор
* (одна тильда и звездочка) регистронезависимая версия
Приведу пример поиска разными способами строк, которые содержат слово text
| Cокращенный синтаксис | Описание | Аналог (I)LIKE |
|---|---|---|
| Проверяет соответствие выражению с учётом регистра | LIKE ‘%text%’ | |
| Проверяет соответствие выражению без учёта регистра | ILIKE ‘%text%’ | |
| ! ‘%text%’ | Проверяет несоответствие выражению с учётом регистра | NOT LIKE ‘%text%’ |
| ! * ‘%text%’ | Проверяет несоответствие выражению без учёта регистра | NOT ILIKE ‘%text%’ |
3. Общие табличные выражения (CTE). Конструкция WITH
Очень удобная конструкция, позволяет поместить результат запроса во временную таблицу и тут же использовать ее.
Примеры будут примитивны, чтобы уловить суть.
Таким способом можно ‘оборачивать’ какие-либо запросы (даже UPDATE, DELETE и INSERT, об этом будет ниже) и использовать их результаты в дальнейшем.
b) Можно создать несколько таблиц, перечисляя их нижеописанным способом
c) Можно даже вложить вышеуказанную конструкцию в еще один (и более) WITH
По производительности следует сказать, что не стоит помещать в секцию WITH данные, которые будут в значительной степени фильтроваться последующими внешними условиями (за пределами скобок запроса), ибо оптимизатор не сможет построить эффективный запрос. Удобнее всего положить в CTE результаты, к которым требуется несколько раз обращаться.
4. Функция array_agg(MyColumn).
Значения в реляционной базе хранятся разрозненно (атрибуты по одному объекту могут быть представлены в нескольких строках). Для передачи данных какому-либо приложению часто возникает необходимость собрать данные в одну строку (ячейку) или массив.
В PostgreSQL для этого существует функция array_agg(), она позволяет собрать в массив данные всего столбца (если выборка из одного столбца).
При использовании GROUP BY в массив попадут данные какого-либо столбца относительно каждой группы.
Сразу опишу еще одну функцию и перейдем к примеру.
array_to_string(array[], ‘;’) позволяет преобразовать массив в строку: первым параметром указывается массив, вторым — удобный нам разделитель в одинарных кавычках (апострофах). В качестве разделителя можно использовать
Выдаст результат:
Выполним обратное действие. Разложим массив в строки при помощи функции UNNEST, заодно продемонстрирую конструкцию SELECT columns INTO table_name. Помещу это в спойлер, чтобы статья не сильно разбухала.
5. Ключевое слово RETURNIG *
указанное после запросов INSERT, UPDATE или DELETE позволяет увидеть строки, которых коснулась модификация (обычно сервер сообщает лишь количество модифицированных строк).
Удобно в связке с BEGIN посмотреть на что именно повлияет запрос, в случае неуверенности в результате или для передачи каких либо id на следующий шаг.
Можно использовать в связке с CTE, организую безумный пример.
Таким образом, выполнится удаление данных, и удаленные значения передадутся на следующий этап. Все зависит от вашей фантазии и целей. Перед применением сложных конструкций обязательно изучите документацию вашей версии СУБД! (при параллельном комбинировании INSERT, UPDATE или DELETE существуют тонкости)
6. Сохранение результата запроса в файл
У команды COPY много разных параметров и назначений, опишу самое простое применение для ознакомления.
7. Выполнение запроса на другой базе
Не так давно узнал, что можно адресовать запрос к другой базе, для этого есть функция dblink (все подробности в мануале)
Если возникает ошибка:
«ERROR: function dblink(unknown, unknown) does not exist»
необходимо выполнить установку расширения следующей командой:
8. Функция similarity
Функция определения схожести одного значения к другому.
Использовал для сопоставления текстовых данных, которые были похожи, но не равны друг другу (имелись опечатки). Сэкономил уйму времени и нервов, сведя к минимуму ручную привязку.
similarity(a, b) выдает дробное число от 0 до 1, чем ближе к 1, тем точнее совпадение.
Перейдем к примеру. С помощью WITH организуем временную таблицу с вымышленными данными (и специально исковерканными для демонстрации функции), и будем сравнивать каждую строку с нашим текстом. В примере ниже будем искать то, что больше похоже на ООО «РОМАШКА» (подставим во второй параметр функции).
Получим следующий результат:
Если возникает ошибка
«ERROR: function similarity(unknown, unknown) does not exist»
необходимо выполнить установку расширения следующей командой:
Сортируем по similarity DESC. Первыми результатами видим наиболее похожие строки (1— полное сходство).
Необязательно выводить значение similarity в SELECT, можно просто использовать его в условии WHERE similarity(c_name, ‘ООО «РОМАШКА»’) >0.7
и самим задавать устраивающий нас параметр.
P.S. Буду признателен, если подскажете какие еще есть способы сопоставления текстовых данных. Пробовал убирать регулярными выражениями все кроме букв/цифр, и сопоставлять по равенству, но такой вариант не срабатывает, если присутствуют опечатки.
9. Оконные функции OVER() (PARTITION BY __ ORDER BY __ )
Почти описав в своем черновике этот очень мощный инструмент, обнаружил (с грустью и радостью), что подобная качественная статья на эту тему уже существует. Не вижу смысла дублировать информацию, поэтому рекомендую обязательно ознакомиться с данной статьей (ссылка — habrahabr.ru/post/268983/, автору низкий поклон ) тем, кто еще не умеет пользоваться оконными функциями SQL.
10. Множественный шаблон для LIKE
Задача. Необходимо отфильтровать список пользователей, имена которых должны соответствовать определенным шаблонам.
Как всегда, представлю простейший пример:
Имеем запрос, который выполняет свою функцию, но становится громоздким при большом количестве фильтров.
Продемонстрирую, как сделать его более компактным:
Можно проделать интересные трюки, используя подобный подход.
Напишите в комментариях, если есть мысли, как еще можно переписать исходный запрос.
11. Несколько полезных функций
NULLIF(a,b)
Возникают ситуации, когда определенное значение нужно трактовать как NULL.
Например, строки нулевой длины ( » — пустые строки) или ноль(0).
Можно написать CASE, но лаконичнее использовать функцию NULLIF, которая имеет 2 параметра, при равенстве которых возвращается NULL, иначе выводит исходное значение.
COALESCE выбирает первое не NULL значение
GREATEST выбирает наибольшее значение из перечисленных
LEAST выбирает наименьшее значение из перечисленных
PG_TYPEOF показывает тип данных столбца
PG_CANCEL_BACKEND останавливаем нежелательные процессы в базе
12. Экранирование символов
Начну с основ.
В SQL строковые значения обрамляются ‘ апострофом (одинарной кавычкой).
Числовые значения можно не обрамлять апострофами, а для разделения дробной части нужно использовать точку, т.к. запятая будет воспринята как разделитель
результат:
Все хорошо, до тех пор пока не требуется выводить сам знак апострофа ‘
Для этого существуют два способа экранирования (известных мне)
результат одинаковый:
В PostgreSQL существуют более удобный способ использовать данные, без экранирования символов. В обрамленной двумя знаками доллара $$ строке можно использовать практически любые символы.
получаю данные в первозданном виде:
Если этого мало, и внутри требуется использовать два символа доллара подряд $$, то Postgres позволяет задать свой «ограничитель». Стоит лишь между двумя долларами написать свой текст, например:
Увидим наш текст:
Для себя этот способ открыл не так давно, когда начал изучать написание функций.
Заключение
Надеюсь, данный материал поможет узнать много нового начинающим и «средничкам». Сам я не являюсь разработчиком, а могу лишь назвать себя любителем SQL, поэтому то, как использовать описанные приемы — решать Вам.
Желаю успехов в изучении SQL. Жду комментариев и благодарю за прочтение!
UPD. Вышло продолжение
Настройка и начало работы с PostgreSQL
Загрузка и установка PostgreSQL
PostgreSQL поддерживает все основные операционные системы. Процесс установки прост, поэтому я постараюсь рассказать о нем как можно быстрее.
EDB больше не предоставляет пакеты для систем GNU/Linux. Вместо этого они рекомендуют вам использовать диспетчер пакетов твоего дистрибутива.
Установщики включают в себя разные компоненты.
Вот самые важные из них:
Windows
Скачав установщик, запусти его как любой другой исполняемый файл. Процесс довольно прямолинеен, но некоторые вещи все же заслуживают внимания.
Диалоговое окно «Выбрать компоненты» позволяет выборочно устанавливать компоненты. Если у тебя нет веской причины что-то менять — оставляй все как есть.
По умолчанию PostgreSQL создает суперпользователя с именем postgres (воспринимай его как учетную запись администратора сервера базы данных).
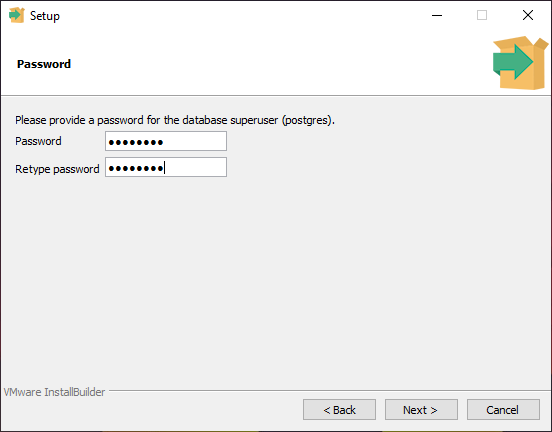
Во время установки тебе нужно будет указать пароль для суперпользователя (root).
Позже ты сможешь создать других пользователей и назначать им отдельные доступы и роли. Мы вернемся к этому позже, а сейчас тебе понадобится учетная запись суперпользователя, чтобы начать использовать СУБД.
После завершения установки ты сможешь запустить SQL Shell, поставляемый с Postgres.
Шаг за шагом ты выберешь сервер, какую базу данных использовать, порт, имя пользователя и пароль.
Используй данные, которые ты вводил на предыдущих шагах.
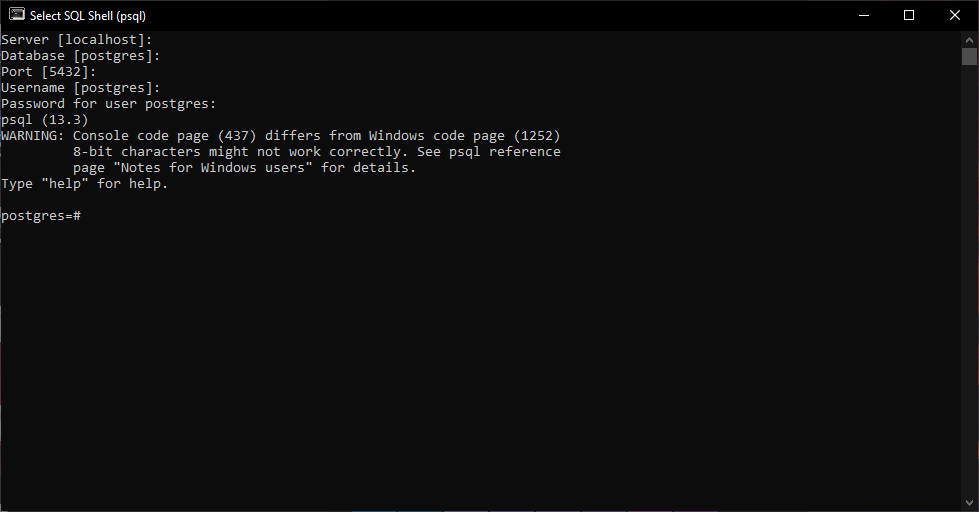
Поздравляю! Настройка для Windows завершена, и скоро мы начнем писать первые SQL запросы.
Ниже список вариантов установки для других операционных систем.
macOS
Для macOS у тебя есть разные варианты. Можно скачать установщик с сайта EDB и запустить его.
После запуска у тебя появится сервер PostgreSQL, готовый к использованию. Завершить работу сервера можно просто закрыв приложение.
GNU/Linux
Ты можешь найти PostgreSQL в репозиториях большинства дистрибутивов Linux. Установить его можно одним щелчком мыши из выбранного графического диспетчера пакетов.
Альтернативно, можно использовать установку через терминал. Ты можешь обратиться к документации твоего дистрибутива для получения дополнительных сведений.
Ubuntu
Fedora
openSUSE
Запуск оболочки PostgreSQL
После установки PostgreSQL, нужно запустить оболочку(shell), с помощью которой ты получишь возможность управлять базой данных.
Открой терминал и введи:
После этого нужно будет ввести пароль суперпользователя, который ты выбрал во время установки.
Как только пароль установлен, база данных PostgreSQL готова к работе!
Если сервер PostgreSQL по какой-то причине не запускается, можешь попробовать запустить его вручную.
Понимание модели клиент-сервер
Я уже упоминал PostgreSQL Server как важный компонент базы данных. Но что такое сервер в этом контексте и зачем он нам нужен?
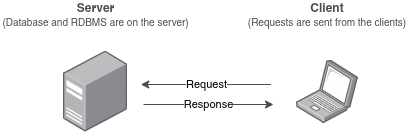
Для начала тебе необходимо понимать модель клиент-сервер.
Почти все СУБД (PostgreSQL, MySQL и другие) следуют клиент-серверной модели. В ней база данных находится на сервере, и клиент отправляет запросы на сервер, который их обрабатывает.
Для разработки любого бекэнда, тебе нужен локальный сервер для экспериментов и тестирования. Этот локальный сервер аналогичен удаленному, но работает прямо на твоем компьютере.
С точки зрения клиента удаленный и локальный сервер идентичны. После разработки и тестирования ты можешь заставить свой продукт взаимодействовать с удаленным сервером вместо локального, просто изменив пару параметров.
Некоторые базы данных не используют эту модель, например SQLite, которая хранит все в простом файле на диске. Это хорошо работает для небольших приложений, но для большинства реальных приложений тебе понадобится архитектура клиент-сервер.
Мета-команды PostgreSQL
Теперь, когда ты все настроил и готов приступить к работе с базой данных, осталось разобрать несколько мета-команд. Это не SQL запросы, а команды специфичные для PostgreSQL.
В других системах управления базами данных есть их аналоги, но их синтаксис немного отличается.
Список всех баз данных
Ввод этой мета-команды в оболочке Postgres выведет:
Это список всех имеющихся баз данных и служебная информация, такая как владелец базы данных, кодировка и права доступа.
Тебе пока не стоит беспокоиться о них. Если хочешь изучить все детали, то проверь официальную документацию.
Подключаемся к базе данных PostgreSQL
Некоторые команды SQL требуют, чтобы ты сначала вошел в базу данных (например, для создания новой таблицы). Ты можешь выбрать, в какую базу данных входить, при запуске SQL Shell.
Полностью в терминале у тебя получится что-то такое:
Получить список всех таблиц в базе данных
Перед выполнением этой команды вам необходимо войти в базу данных.
Ты можешь увидеть имя таблицы и некоторую другую информацию, такую как схема (мы обсудим схемы в более сложных руководствах) и владельца.
Владелец (owner) — это пользователь, который создал таблицу.
Если ты создаешь других пользователей и используешь их для создания таблиц, то в последнем столбце будут именно они.
Список пользователей и ролей
Обрати внимание, что первый столбец называется — роль (role name). И весь вывод на экран называется “список ролей” (List of roles), а не список пользователей.
В PostgreSQL пользователи и роли практически одинаковы.
У ролей есть атрибуты, которые определяют их разрешения, такие как создание баз данных или даже создание других новых ролей.
Любая роль с атрибутом LOGIN может рассматриваться, как пользователь.
Здесь мы видим только одну роль, суперпользователя по умолчанию.
В реальном мире все будет иначе, потому что использовать только суперпользователя все время опасно. Вместо этого создают другие роли с меньшими привилегиями. Это гарантирует, что никто не совершит нежелательных действий по ошибке.
Если у одной из ролей есть доступ только на чтение данных, то с помощью этой роли будет невозможно удалить таблицу или поле.
Твой первый SQL оператор
Наконец, мы все настроили и готовы к работе и знаем основные мета-команды, специфичные для PostgreSQL.
Теперь приступим к изучению языка запросов SQL.
Я покажу тебе несколько базовых примеров, чтобы разобраться в структурированном языке запросов и получить представление о SQL. А более подробно мы рассмотрим операции CRUD это в следующей статье.
Создание новой базы данных
Команды и ключевые слова SQL обычно пишутся в верхнем регистре.
На самом деле это не является обязательным требованием, и обычно они нечувствительны к регистру.
То есть ты мог бы написать
И все сработало бы нормально.
Но при написании операторов SQL обычно предпочтительнее прописные буквы. Это хорошая практика, потому что она может помочь тебе визуально отличить ключевые слова SQL от других частей оператора, таких как имена таблиц и столбцов.
Для мета-команд PostgreSQL точка с запятой не нужна.
Создание таблиц
После того как ты создал новую базу данных, можно приступать к созданию таблиц.
Теперь, когда ты подключился к базе данных (обратите внимание, что приглашение оболочки SQL теперь включает имя активной базы данных), ты готов создать свою первую таблицу.
Таблица создается с помощью команды CREATE TABLE, за которой следует список столбцов таблицы и их типы данных в круглых скобках:
После создания таблицы перейдем к добавлению данных.
Вставка данных в таблицы PostgreSQL
Чтобы добавить данные в таблицу, используют команду INSERT INTO следующим образом:
Посмотрим на команду INSERT INTO подробнее:
Выборка данных из SQL таблицы
Теперь, когда ты добавил в таблицу первую запись, ты можешь использовать SQL для получения содержимого таблицы.
Для ситуаций когда ты хочешь выбрать все столбцы которые есть в таблице, ты можешь поставить звездочку вместо списка полей.
Звездочка означает: выбрать все столбцы. Результат останется прежним.
Ты должен обратить внимание на то, как команда SELECT выбирает столбцы и строки. Столбцы указываются в виде списка и разделяются запятыми. Затем команда переходит к выбору запрошенных строк.
Если условия не указаны (как в этом случае), будут выбраны все строки в таблице.
Позже мы увидим, как использовать условия с командой WHERE для создания эффективных запросов.
Обновление данных в PostgreSQL
Представь, что ты запустил свое потрясающее приложение для магазина и получили первый заказ на один из продуктов.
Первое, что нужно сделать — это обновить доступное количество в вашем инвентаре, чтобы в дальнейшем у вас не возникли проблемы с отсутствием товара на складе.
Для обновления данных ты можешь использовать команду UPDATE :
После SET — пишем имена столбцов, которые хотим обновить.
За ними — знак равенства и новое обновленное значение.
Также ты можешь обновить сразу несколько столбцов, разделив их запятыми:
Но стоп, какие строки обновляются этой командой?
Удаление данных из SQL таблицы
Теперь рассмотрим случай, когда ты прекратил продажу определенного продукта и захотел полностью удалить его из своей базы данных.
Для этого можно использовать команду DELETE :
Удаление таблиц в PostgreSQL
Если вдруг ты решил изменить структуру базы и для этого нужно удалить всю таблицу, то тебе подойдет команда DROP TABLE :
Это приведет к удалению всей таблицы products из базы данных.
Я бы не позавидовал тому, кто “случайно” удалит не ту таблицу из базы данных.
Удаление баз данных PostgreSQL
Точно так же ты можешь удалить из системы всю базу данных:
Заключение
Поздравляю, у тебя все получилось!
Ты установил и запустили PostgreSQL. Ты изучил основные команды SQL и проделали с ними несколько интересных вещей.
Эти несколько простых команд — основа, которую ты будешь использовать большую часть времени при взаимодействии с базами данных, поэтому тебе следует пойти и потренироваться и изучить самостоятельно. В следующий раз мы погрузимся глубже и обсудим Базы данных, роли и таблицы в PostgreSQL



