Внутренняя работа HashMap в Java
В этой статье мы увидим, как изнутри работают методы get и put в коллекции HashMap. Какие операции выполняются. Как происходит хеширование. Как значение извлекается по ключу. Как хранятся пары ключ-значение.
Как и в предыдущей статье, HashMap содержит массив Node и Node может представлять класс, содержащий следующие объекты:
Теперь мы увидим, как все это работает. Для начала мы рассмотрим процесс хеширования.
Хэширование
Здесь я использую свой собственный класс Key и таким образом могу переопределить метод hashCode() для демонстрации различных сценариев. Мой класс Key:
Здесь переопределенный метод hashCode() возвращает ASCII код первого символа строки. Таким образом, если первые символы строки одинаковые, то и хэш коды будут одинаковыми. Не стоит использовать подобную логику в своих программах.
Этот код создан исключительно для демонстрации. Поскольку HashCode допускает ключ типа null, хэш код null всегда будет равен 0.
Метод hashCode()
Метод equals()
Метод equals используется для проверки двух объектов на равенство. Метод реализованн в классе Object. Вы можете переопределить его в своем собственном классе. В классе HashMap метод equals() используется для проверки равенства ключей. В случае, если ключи равны, метод equals() возвращает true, иначе false.
Корзины (Buckets)
Вычисление индекса в HashMap
Хэш код ключа может быть достаточно большим для создания массива. Сгенерированный хэш код может быть в диапазоне целочисленного типа и если мы создадим массив такого размера, то легко получим исключение outOfMemoryException. Потому мы генерируем индекс для минимизации размера массива. По сути для вычисления индекса выполняется следующая операция:
где n равна числу bucket или значению длины массива. В нашем примере я рассматриваю n, как значение по умолчанию равное 16.
HashMap: 
Вычислить значение ключа <"vishal">. Оно будет сгенерированно, как 118.
Создать объект node.
Поместить объект в позицию с индексом 6, если место свободно.
Теперь HashMap выглядит примерно так:
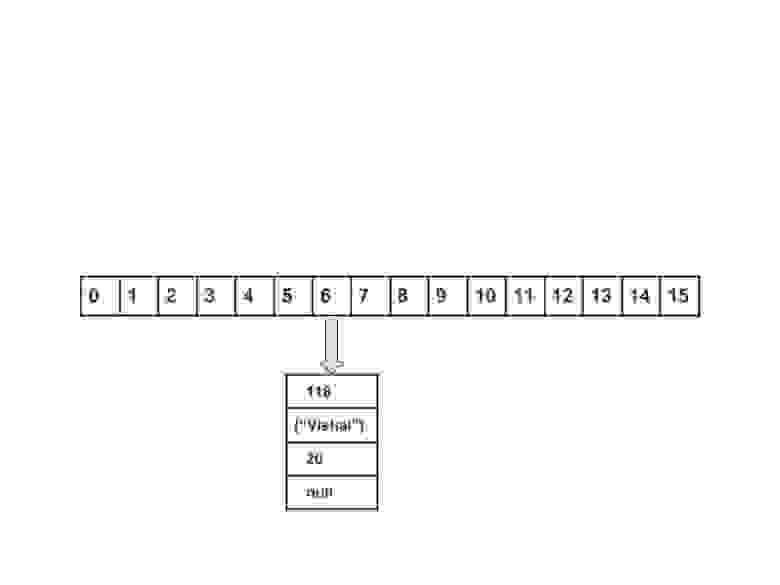
Вычислить значение ключа <"sachin">. Оно будет сгенерированно, как 115.
Создать объект node.
Поместить объект в позицию с индексом 3, если место свободно.
Теперь HashMap выглядит примерно так:

Вычислить значение ключа <"vaibhav">. Оно будет сгенерированно, как 118.
Создать объект node.
Поместить объект в позицию с индексом 6, если место свободно.
В данном случае в позиции с индексом 6 уже существует другой объект, этот случай называется коллизией.
В таком случае проверям с помощью методов hashCode() и equals(), что оба ключа одинаковы.
Если ключи одинаковы, заменить текущее значение новым.
Иначе связать новый и старый объекты с помощью структуры данных «связанный список», указав ссылку на следующий объект в текущем и сохранить оба под индексом 6.
Теперь HashMap выглядит примерно так:

[примечание от автора перевода] Изображение взято из оригинальной статьи и изначально содержит ошибку. Ссылка на следующий объект в объекте vishal с индексом 6 не равна null, в ней содержится указатель на объект vaibhav.
Вычислить хэш код объекта <“sachin”>. Он был сгенерирован, как 115.
В нашем случае элемент найден и возвращаемое значение равно 30.
Вычислить хэш код объекта <"vaibhav">. Он был сгенерирован, как 118.
В данном случае он не найден и следующий объект node не равен null.
Если следующий объект node равен null, возвращаем null.
Если следующий объект node не равен null, переходим к нему и повторяем первые три шага до тех пор, пока элемент не будет найден или следующий объект node не будет равен null.
Изменения в Java 8
Для исправления этой проблемы в Java 8 после достижения определенного порога вместо связанных списков используются сбалансированные деревья. Это означает, что HashMap в начале сохраняет объекты в связанном списке, но после того, как колличество элементов в хэше достигает определенного порога происходит переход к сбалансированным деревьям. Что улучшает производительность в худшем случае с O(n) до O(log n).
Структуры данных в картинках. HashMap
Приветствую вас, хабрачитатели!
Продолжаю попытки визуализировать структуры данных в Java. В предыдущих сериях мы уже ознакомились с ArrayList и LinkedList, сегодня же рассмотрим HashMap.

HashMap — основан на хэш-таблицах, реализует интерфейс Map (что подразумевает хранение данных в виде пар ключ/значение). Ключи и значения могут быть любых типов, в том числе и null. Данная реализация не дает гарантий относительно порядка элементов с течением времени. Разрешение коллизий осуществляется с помощью метода цепочек.
Создание объекта
Вы можете указать свои емкость и коэффициент загрузки, используя конструкторы HashMap(capacity) и HashMap(capacity, loadFactor). Максимальная емкость, которую вы сможете установить, равна половине максимального значения int (1073741824).
Добавление элементов
Комментарий из исходников объясняет, каких результатов стоит ожидать — метод hash(key) гарантирует что полученные хэш-коды, будут иметь только ограниченное количество коллизий (примерно 8, при дефолтном значении коэффициента загрузки).
В моем случае, для ключа со значением »0» метод hashCode() вернул значение 48, в итоге:
При значении хэша 51 и размере таблице 16, мы получаем индекс в массиве:
Для того чтобы продемонстрировать, как заполняется HashMap, добавим еще несколько элементов.
Footprint
Object size: 376 bytes
Footprint
Object size: 496 bytes
Resize и Transfer
Когда массив table[] заполняется до предельного значения, его размер увеличивается вдвое и происходит перераспределение элементов. Как вы сами можете убедиться, ничего сложного в методах resize(capacity) и transfer(newTable) нет.
Метод transfer() перебирает все элементы текущего хранилища, пересчитывает их индексы (с учетом нового размера) и перераспределяет элементы по новому массиву.
Если в исходный hashmap добавить, скажем, еще 15 элементов, то в результате размер будет увеличен и распределение элементов изменится.
Удаление элементов
У HashMap есть такая же «проблема» как и у ArrayList — при удалении элементов размер массива table[] не уменьшается. И если в ArrayList предусмотрен метод trimToSize(), то в HashMap таких методов нет (хотя, как сказал один мой коллега — «А может оно и не надо?«).
Небольшой тест, для демонстрации того что написано выше. Исходный объект занимает 496 байт. Добавим, например, 150 элементов.
Теперь удалим те же 150 элементов, и снова замерим.
Как видно, размер даже близко не вернулся к исходному. Если есть желание/потребность исправить ситуацию, можно, например, воспользоваться конструктором HashMap(Map).
Итераторы
HashMap имеет встроенные итераторы, такие, что вы можете получить список всех ключей keySet(), всех значений values() или же все пары ключ/значение entrySet(). Ниже представлены некоторые варианты для перебора элементов:
Стоит помнить, что если в ходе работы итератора HashMap был изменен (без использования собственным методов итератора), то результат перебора элементов будет непредсказуемым.
Итоги
— Добавление элемента выполняется за время O(1), потому как новые элементы вставляются в начало цепочки;
— Операции получения и удаления элемента могут выполняться за время O(1), если хэш-функция равномерно распределяет элементы и отсутствуют коллизии. Среднее же время работы будет Θ(1 + α), где α — коэффициент загрузки. В самом худшем случае, время выполнения может составить Θ(n) (все элементы в одной цепочке);
— Ключи и значения могут быть любых типов, в том числе и null. Для хранения примитивных типов используются соответствующие классы-оберки;
— Не синхронизирован.
Ссылки
Инструменты для замеров — memory-measurer и Guava (Google Core Libraries).
Русские Блоги
Реализация Java-Collection-HashMap и разница между HashTable, LinkedHashMap, WeakHashMap
В предыдущей статье была представлена структура класса коллекции и связанные с ним различия классов. В этом разделе давайте узнаем, как реализован HashMap, принцип реализации хеш-таблицы, процесс расширения и древовидности (на основе JDK 1.8).
Базовая структура хранения HashMap
Затем используйте картинку, чтобы показать структуру хранения HashMap:

Очевидно, HashMap на самом деле является » Массив плюс связанный список Связанный список фактически реализуется по ссылке. Эта структура также называется «хеш-таблицей» или «хеш-таблицей».
В хеш-таблице хранение элементов не последовательное, а реализовано по хеш-алгоритму.
Принцип хеш-таблицы
Массив : Используйте единицу непрерывного хранения для хранения данных. Для поиска по заданному индексу сложность времени составляет O (1); для поиска по заданному значению необходимо пройти по массиву и сравнить заданные ключевые слова и элементы массива один за другим. Сложность по времени составляет O (n). Конечно, для Для порядковых массивов можно использовать двоичный поиск, поиск с интерполяцией, поиск Фибоначчи и т. Д., Чтобы увеличить сложность поиска до O (logn); для общих операций вставки и удаления, которые включают перемещение элементов массива, средняя сложность Также O (n)
Линейный связанный список : Для таких операций, как добавление и удаление связанного списка (после нахождения указанной позиции операции), необходимо обрабатывать только ссылки между узлами. Сложность времени составляет O (1), и операция поиска должна проходить по связанному списку один за другим для сравнения. Сложность O (n)
Двоичное дерево : Для относительно сбалансированного упорядоченного двоичного дерева, операций вставки, поиска, удаления и других операций над ним средняя сложность составляет O (logn).
Хеш-таблица : По сравнению с несколькими вышеупомянутыми структурами данных, производительность добавления, удаления, поиска и других операций в хеш-таблице очень высока. Без учета конфликта хешей для завершения требуется только одно позиционирование, а временная сложность равна O (1) Теперь давайте посмотрим, как хеш-таблица достигает удивительного постоянного порядка O (1).
Например, если мы хотим добавить или найти определенный элемент, мы можем завершить операцию, сопоставив ключ текущего элемента с определенной позицией в массиве с помощью определенной функции и поместив индекс массива один раз.
Место хранения = f (ключевое слово)

Операция поиска такая же, сначала вычисляется фактический адрес хранилища с помощью хэш-функции, а затем извлекается из соответствующего адреса в массиве.
Коллизия хэша
Принцип реализации HashMap JAVA
В JAVA вызовите каждую позицию в массивебочка, И все данные за корзиной называютсяbin (Из JDK1.8).
Сначала посмотрите на некоторые из наиболее важных переменных (взятых из JDK 1.8):
table
Хэш-таблица, в которой хранятся элементы, представляет собой массив. Каждый элемент массива называется корзиной. В корзине можно использовать линейный связанный список или двоичное дерево. Элементы в корзине называются корзинами.
Русские Блоги
Структура данных в Java-HashMap
Структура данных в Java-HashMap
Каталог статей
1. HashMap
1.1 Введение в HashMap
1.1.1 Введение в HashMap
1.1.2 Схема наследования HashMap

HashMap через наследование AbstractMap Достигнуто Map Интерфейс, а также реализует Map интерфейс
Это избыточная операция с точки зрения взаимосвязи реализации интерфейса.
Но нужно помнить об одном при использованииИнтерфейс реализации получения отраженияВ то время, если он отображается не для реализации интерфейса, а для реализации интерфейса через наследование, тип интерфейса не будет получен, который используетсяДинамический проксиОбращать внимание
HashMap реализован Serializable Интерфейс, можно пройти java.io.ObjectStream Сериализовать
HashMap реализован Cloneable Интерфейс, реализованныйМелкая копия, Может быть подтверждено следующим кодом:
1.2 Структура композиции HashMap
1.2.1 Базовая структура данных Hashmap
(1) Хеш-таблица
Хеш-таблица также становится хеш-таблицей, в основе которой лежит ключ hash() Обработка функции, значение отображается в определенное место в хеш-таблице, и это местоположение используется в качестве места хранения ключа. Независимо от того, где он существует, для поиска местоположения требуется только одно вычисление хеш-функции. Временная сложность всего процесса поиска составляет O ( 1 ) O(1) O ( 1 )
HashMap использует массив в качестве хеш-таблицы для хранения ключевой информации hash ()

(2) Связанный список
потому как hash() Функция состоит в том, чтобы отобразить значение ключа в ограниченное пространство, если hash() Неполный дизайн конфликтов функций или слишком много элементов, хранящихся в хэш-таблице, неизбежно приведет к одному и тому же хеш-значению разных элементов, то есть к конфликтам позиций. В настоящее время мы обычно используем следующие методы:

(3) Красно-черное дерево

2. Анализ исходного кода HashMap
2.1 Анализ исходного кода атрибута HashMap
2.1.1 Статические константы в HashMap
(1) Длина таблицы по умолчанию
(2) Максимальная длина стола
(3) Коэффициент нагрузки по умолчанию
(4) Пороговая длина дерева связанного списка
(5) Пороговое количество элементов дерева HashMap.
(6) Порог дерева сводится к связанному списку
2.1.2 Свойства в HashMap
(1) Количество элементов HashMap
(2) Количество изменений в структуре хеш-таблицы.
(3) Порог расширения
(4) Коэффициент нагрузки
2.1.3 Узлы хранения в HashMap
(1) Исходный код класса статического узла
Node Реализован класс Node Map.Entry Статический внутренний класс интерфейса, который в основном содержит:
Переписанный hash() Метод передачи ключа и значения Objects.hashCode(Object o) После леченияпротивОперация, изготовление hash() Отображение функций более случайное и однородное
Переписанный equals В методе только входящий узел является собственным узлом или key против value Когда вызывается метод equals, результат истинный(В основном используется для сравнения при поиске элементов позже)
2.1.4 Хеш-таблица
(1) Исходный код хэш-таблицы
Исходный код определения хеш-таблицы:
Чтобы иметь возможность найти местоположение сегмента путем определения вычисленного хэш-кода, нижний уровень HashMap использует массив типов узлов Node в качестве сегмента.
временная модификация будет пропущена во время сериализации
(2) Определите расположение ствола
(3) Определение длины
Исходный код метода расчета длины хеш-таблицы:
Функция этого метода состоит в том, чтобы вернуть число, большее или равное текущему значению cap путем передачи емкости при инициализации, и это число должно быть степенью 2
Этот метод продолжает движение вправо, а затем выполняет операцию «или», вы можетеЗаполните 0 бит после первого ненулевого бита во входящей шапке, Становится 0..11. 1 В виде 2 n из два Заранее система Немного количество + 1 − 1 2 ^ <Двоичные цифры n + 1>-1 2 n из два Заранее система Немного количество + 1 − 1
Длина хеш-таблицы должна быть степенью двойки.
(4) Расчет хеш-значения: hash(K key)
Если ключ равен нулю, хеш-значение равно 0, а результат вычисления позиции также равен 0 (как видно из первого случая метода putVal), он будет заменен table[0] Элементы, битовый ключ сегмента которых равен нулю
Когда длина таблицы относительно мала, алгоритм из предыдущей позиции index = (table.length-1)|node.hash() Можно видеть, что если он не обрабатывается, вычисленный индекс зависит только от последних нескольких бит хэша узла (двоичной длины table.length-1), что значительно увеличит вероятность того, что результаты позиционирования различных элементов будут одинаковыми.
Старшие 16 бит результата h >> 16 равны 0, (h = key.hashCode()) ^ (h >>> 16) Старшие 16 бит хэша результата могут быть старшими 16 битами key.hashCode (), поэтомуСтаршие 16 бит также участвуют в вычислении хэш-значения, увеличивая случайность младших 16 бит.
2.2 Изменения в данных HashMap
2.2.1 Анализ метода строительства
(1) HashMap(int initialCapacity, float loadFactor)
(2) Другие методы строительства
Исходный код другого метода строительства
putMapEntries Исходный код метода:
2.2.2 Анализ метода put для добавления пар ключ-значение
(1) put(K key, V value)
Метод матрешки, метод сначала вычисляет вызов hash() Метод вычисления хеш-значения (не key.hashCode ()), вызов putVal ЧтобызаменитьСпособ выполнения операции вставки узла, возврат значения предыдущего узла
(2) putIfAbsent
Метод куклы, вычисление хеш-значения, вызов putVal ЧтобыБез заменыВставьте узел в путь и верните значение предыдущего узла
Кукольный метод, вызов putMapEntries(m, true) Реализуйте добавление всех пар ключ-значение входящей карты
(3) putVal
исходный код putVal
Логика выполнения метода:
2.2.3 Анализ метода изменения размера раскрытия таблицы хеш-таблицы
(1) Причины расширения
(2) Ядро resize метод
Исходный код метода изменения размера:
Определите новую емкость таблицы и новую логику порога расширения:
в случае: OldTab! = Null, что указывает на то, что массив был создан перед расширением, и в это время он начинает обход oldTab.for(j = 0;j
сделать oldTab[j] = null Удобный сборщик мусора для утилизации старых массивов
* Если: * eдеревоКорневой узел, вызовите ((TreeNode )e).split(this, newTab, j, oldCap); Чтобы разместить узлы в дереве в новой таблице
* Если: * eСвязанный списокГоловной узел, создайте 4 узла связанного списка loHead,loTail,hiHead,hiTail
Начать цикл: создать узел next = e.next
Наконец, установите для конечных узлов двух связанных списков значение null.
будут newTab[j] = loHead , newTab[j+oldCap] = hiHead
2.2.4 Анализ метода удаления пары ключ-значение
(1) remove(K) метод
Doll, вызовите метод removeNode, получите возвращенный удаленный узел и верните значение узла.
(2) remove(K,V) метод
Doll, вызовите метод removeNode, верните, успешно ли удаление
(3) Ядро removeNode метод
2.2.5 Анализ метода замены
(1) replace(K,V)
перечислить getNode Метод пройденСравнить ключЧтобы найти узел, который необходимо заменить, присвойте значение узлу и верните старое значение; если не найдено, верните ноль
(2) replace(K key, V oldValue, V newValue)
перечислить getNode Метод пройденСравните ключ и значениеЧтобы найти заменяемый узел, присвойте узлу newValue, верните true, если не найден, верните false
2.2.6 Метод вычисления K-отображения
(1) compute метод
инструкции
(2) computeIfAbsent метод
Метод ifНе обнаруженаУзел, соответствующий ключу, добавит новый узел Node(key,mappingFunction.apply(key,value)) В HashMap, если он существует, не выполняйте эту операцию и возвращайте null;Если результат сопоставления равен нулю, узел будет удален
инструкции
(3) computeIfPresent метод
Метод ifобнаруженУзел, соответствующий ключу, добавит новый узел Node(key,mappingFunction.apply(key,value)) В HashMap, если он не существует, не выполняйте эту операцию и верните null;Если результат сопоставления равен нулю, узел будет удален
инструкции
2.2.7 Метод слияния карт K-V
(1) Метод слияния
Этот метод аналогичен вычислению, за исключением того, что ключ и значение Чтобы найти соответствующий узел, замените его, если он найден, вставьте новый узел, если он не найден. Node(key,value)
Если oldValue имеет значение null или узел не существует, напрямую берется параметр value (а не отображаемое значение) Как значение узла
Аналогично, как частный случай,Если вычисленное значение равно нулю, удалите узел
инструкции
2.2.8 Расход траверса для каждого метода
(1) forEach метод
2.2.9 Очистить метод очистки
(1) Очистить метод
Определите, инициализирована ли таблица, если она не пуста, установите для каждой позиции значение null и дождитесь, пока JVM освободит каждый узел.
2.3 Получение информации в HashMap
2.3.1 Метод получения значения, анализ метода
(1) get метод
В методе матрешки сначала используйте хэш-функцию, чтобы получить хеш-значение ключа, getNode, чтобы найти узел узла, если он найден, он возвращает значение значения, а если он не найден, возвращает ноль
(2) getOrDefault метод
Метод матрешки похож на метод get, за исключением того, что если узел не найден, возвращается значение по умолчанию, переданное в
(2) Ядро getNode метод
2.3.2 Проверьте, включен ли ключ, значение containsXX метод
(1) containsKey(K)
Кукольный метод, вызов getNode Поиск метода, возврат, найден ли узел
(2) containsValue(V)
2.3.3 Проверить размер
(1) isEmpty метод
(2) size метод
2.4 Другие методы
2.4.1 Сериализация и десериализация
(1) Введение в метод сериализации в HashMap
Чтобы обеспечить кроссплатформенность JVM и предотвратить результат сериализации и десериализации из-за того, что разные машины являются результатом обычного построения, используются многие атрибуты данных в HashMap. transient Модификация, она будет пропущена во время сериализации, поэтому вам нужно переписать метод, чтобы настроить запись и чтение сериализованных данных.
Для удобства HashMap также предоставляет методы сериализации и десериализации (исходный код здесь не размещен, вы можете перейти на jdk, чтобы увидеть):
(2) Эффект метода



